Содержание
1. Введение ____________________________________________________ 2
2. Общие сведения о проблеме ____________________________________ 3
3. Краткий обзор
________________________________________________ 5
3.1. Продукты Oracle
________________________________________ 5
3.2. Продукты Convera _______________________________________9
3.3. Система ConExT ________________________________________ 11
3.4. OntosMiner
_____________________________________________ 16
3.5.
Язык
OWL
_____________________________________________ 18
3.5.1. Общие сведения
_____________________________________18
3.5.2. Веб-онтологии OWL _________________________________19
3.6. Медиалогия ____________________________________________ 26
3.7. Программа Starlight 3.0 ___________________________________29
3.8. UIMA(IBM) ___________________________________________ 30
3.8.1. Общие сведения _____________________________________ 30
3.8.2. Пример простого приложения в UIMA __________________ 32
3.8.3. Перспективы развития UIMA _________________________ 32
3.9. Комментарии к обзору ___________________________________ 34
3.9.1. Основные решаемые задачи ____________________________34
3.9.2. Общие выводы _______________________________________36
4. Проекты, поддержанные РФФИ_________ ________________________ 39
4.1. Проект 2002-2004 гг. _____________________________________ 39
4.1.1. Основная концепция __________________________________ 39
4.1.2. Априорная модель данных _____________________________42
4.1.3. Тестирование ________________________________________ 45
4.2. Проект 2005-2007 гг. _____________________________________ 47
4.3. Рекомендации по использовании результатов проектов ________ 48
4.4. Данные и знания ________________________________________51
5. Cервисно-ориентированная архитектура __________________________54
5.1. Общие сведения о СОА __________________________________54
5.2. Новая коммуникационная подсистема Windows – Indigo ______ 56
6. О компьютерной лингвистике
__________________________________ 59
7. Когнитивные методы принятия решений
_________________________ 61
7.1. Когнитивные методы в социально-политической сфере _______63
7.2. Когнитивные методы в экономике _________________________64
8. Заключение
__________________________________________________ 67
Литература _______________________________________________ 68
Дополнительные материалы 2006 – 2007 гг._________________________70
1. Введение
Главная
цель данных материалов – дать общее представление о современном состоянии
проблемы анализа больших объемов
текстовой информации из глобальной сети и алгоритмов принятия решений на
основе когнитивных методов. Основное
внимание уделялось содержательной стороне проблемы, в качестве фоновой рассматривалась задача
реализации соответствующих алгоритмов на параллельных системах (сеть
кластеров). При подготовке использованы материалы до
Материалы представляют собой в
основном извлечения из описания соответствующих систем, при этом по возможности
соблюдался баланс между слишком поверхностном описании и нагромождением деталей,
за которыми трудно полноценно оценить предлагаемые концепции.
Материалы не подвергались существенной аналитической обработке, они рассматривались как некоторый первичный экспериментальный базис. Тем не менее экспресс-анализ данных материалов укрепил уверенность автора в перспективности выбранного направления фундаментальных исследований, но надеемся не лишил автора способности видеть трудности проблемы.
2. Общие
сведения о проблеме
Одна
из основных целей анализа больших объемов
текстовой информации – высокорелевантный поиск в сети Интернет
и представление
неструктурированной текстовой информации
из сети Интернет в
структурированном виде, позволяющем осуществить последующую обработку (в
частности оперативный анализ – OLAP и интеллектуальный анализ – Data Mining) для систем принятия решений. Актуальность
данной проблемы определяется тем, что в
настоящее время соотношение между информацией, которую можно "читать",
и той, что можно "считать", составляет порядка 80:20. Аналитическая
обработка неструктурированной информации ориентирована в первую очередь на тексты, хотя в обозримой перспективе речь
может идти также о графике, звуке и видео.
Анализ
больших объемов текстовой информации по
сути является одной из частных проблем общей и фундаментальной проблемы
автоматической обработки естественного языка (ЕЯ). Другими частными проблемами
такого класса являются, например, проблема машинного перевода,
вопросно-ответные системы с ЕЯ-интерфейсом (в частности, доступ к базам данных
на ЕЯ), проблема автоматического индексирования документов, проблема
содержательного поиска в Интернет (более глубокого и тонкого, чем по ключевым
словам) и т.п.
По
мнению многих специалистов в области искусственного интеллекта (ИИ) решение
всех этих проблем существенно зависит от проблемы представления знаний (knowledge representation)
или как сейчас модно говорить от выбора онтологии предметной области. Эта центральная проблема ИИ еще далека от
удовлетворительного решения, хотя отдельные подходы были развиты
десятилетия назад (формулы исчисления
предикатов, семантические сети, фреймы, продукционные правила). Проблема представления знаний практически не
обсуждается в рамках данных материалов, один из аспектов этой проблемы очень
кратко затронут в заключении.
Проблема
анализа больших объемов текстовой информации из глобальной сети приобретает особую актуальность в связи
с постоянным ростом объемов информации
не только в Интернет, но и в
масштабе отдельных организаций. Аналитические отделы как в государственных
учреждениях (например ФАПСИ), так и в
крупных коммерческих структурах ежедневно получают много мегабайт текстовой
информации ( например, из СМИ). По этой информации достаточно оперативно
(обычно также ежедневно) аналитики представляют
руководству обобщенные сводки, в концентрированном виде отображающие суть
текстов.
Автоматизация
анализа позволяет существенно облегчить задачу аналитика и такие системы были разработаны и используются по
настоящее время, но их качество уже не удовлетворяет пользователей по мере
роста объемов текстов. Кроме того, c
появлением систем извлечения знаний (Data Mining) аналитика интересуют
автоматически выявляемые закономерности в данных. Однако системы Data Mining работают со структурированной информацией (в
базах данных, точнее в хранилищах данных - Data Warehouse). Поэтому помимо получения оперативных
сводок по массивам текстов, результат автоматического анализа целесообразно
представить в структурированном виде и далее использовать средства извлечения
знаний.
К
когнитивным методам и моделям анализа данных наряду с Data Mining относится и OLAP-технология (оперативный анализ данных). Эта
технология также работает лишь со структурированной информацией и следовательно
результаты анализа больших объемов текстовой информации целесообразно
использовать и для нее. Алгоритмы реализации OLAP и Data Mining не рассматриваются в данных материалах.
Подчеркнем, что все вышеупомянутые алгоритмы в конечном счете
включаются в системы поддержки принятия решений (DSS,
Decision Support System) и должны обеспечить компетентных лиц
достоверной, полной и достаточно компактной информацией для принятия важных
решений. Хотя как указано выше подходы OLAP и Data Mining ориентированы на структурированные данные, развитые в них механизмы могут быть полезны и при
обработке текстовой информации
OLAP – технология оперативной аналитической
обработки данных, обеспечивающая быстрый и наглядный ответ на достаточно
произвольные запросы аналитика. Цель OLAP анализа – проверка возникающих у аналитика гипотез. Технология OLAP оперирует с многомерными моделями данных
(т.н. гиперкубы ) и включает такие базовые операции как срез, вращение,
консолидация и детализация. Типичное время обработки запроса в OLAP-системе – несколько секунд (1 - 3).
Data Mining – технология позволяет обнаружить в данных
скрытые закономерности, практически полезные и доступные для интерпретации
человеком. Технология ориентирована на получение достаточно нетривиальных
закономерностей, которые трудно получить более простыми способами (например,
визуальным просмотром). Основными задачами анализа с привлечением Data Mining являются: классификация/регрессия,
нахождение частых зависимостей между объектами или событиями (ассоцитивные
правила), выделение групп объектов (кластеризация).
Типичные сферы практического
применения Data Mining:
-
Интернет-технологии
- рекомендательные системы
интернет-магазинов
- автоматическое распределение клиентов по
классам
- обнаружение безопасности при операциях с
пластиковыми картами
- персонализация посетителей Web-сайтов
- Торговля
- анализ рыночных корзин
- связи между покупками и временем
- сегментация рынка
- Телекоммуникации
- выявление категорий клиентов с похожими
стереотипами поведения
- Промышленость
- прогнозирование качества изделий от
параметров технологического процесса
- Медицина
- предсказание исхода назначенного курса
лечения
- исследование закономерностей в
генетических структурах
- исследование новых препаратов на
дофармакологической фазе
- Банковское дело
- решение о кредитоспособности клиента
(тысячи американских банков)
- Страховой бизнес
- предсказание страховых рисков
3. Краткий обзор
Цель обзора – получение относительно представительного первичного базиса для экспресс-анализ проблемы обработки больших объемов текстовой информации и разработок коммерческого уровня (в основном на Российском рынке).
3.1. Продукты Oracle
Лидер мирового рынка СУБД Oracle уже снабдил разработчиков
информационных систем рядом передовых технологий [1]. Речь идет о interMedia Text, входящем в состав СУБД
ORACLE8i, при использовании которого обработка текста сочетается со всеми
возможностями, предоставленными пользователю Oracle для работы с реляционными
базами данных. В частности, при написании приложений стало возможно использовать
SQL с развитым языком запросов к полнотекстовой информации.
Не останавливаясь подробно на всех уникальных возможностях
interMedia Text, информацию о которых можно получить на сайтах www.oracle.com и www.oracle.ru, отметим, что, к
сожалению, большинство из них оказывается доступно в полной мере лишь на
английском языке.
Адаптацией технологий Oracle к русскоязычным полнотекстовым
базам данных занимаются специалисты компании «Гарант-Парк-Интернет». Продукт
этой компании под названием Russian Context Optimizer (RCO) предназначен для
совместного использования с interMedia Text.
RCO - Серия
продуктов, выпускаемых под маркой RCOТМ, предназначена для поддержки
широкого класса систем, использующих средства поиска и анализа текстовой
информации, таких, как информационно-поисковые и аналитические системы,
электронные архивы и системы управления документооборотом. Продукты серии RCO
задействуют передовые технологии обработки текста, лингвистические и математические
алгоритмы, которые могут быть использованы для решения широкого класса задач:
от контекстного поиска документов с учетом всех словоформ, синонимов и опечаток
до создания систем поддержки принятия экспертных решений на основе анализа информационных
массивов.
RCO for Oracle, RCO for BackOffice, RC WEB и т.д. поисковые машины, инструментарии разработчика и аналитика.
RCO for Oracle ‑ единственный на рынке продукт, позволяющий значительно расширить возможности OracleText при работе c базами данных, содержащими документы на русском языке. RCO for Oracle задействует такие технологии, как лексико-грамматический и статистический анализ текста, алгоритмы автоматической классификации, рубрицирования и реферирования; нечеткого поиска, реализуя все существующие возможности OracleText для русского языка.
RCO for BackOffice Продукт позволяет расширить возможности
Microsoft BackOffice (MS SharePoint Portal, MS Indexing Service, MS Exchange
Server и MS SQL Server) при работе с документами на русском языке, обеспечивая
поиск с учетом всех грамматических форм слов на основе морфологического
анализа.
RC WEB![]() Продукт представляет поисковую систему,
обладающую возможностями как контекстного, так и реляционного поиска. Russian
Context позволяет искать документы с учетом морфологии русского и английского
языков, используя SQL-подобный язык запросов и комбинируя поисковые ограничения
на контекст с ограничениями на заданные атрибуты документов. Продукт работает в
среде Windows.
Продукт представляет поисковую систему,
обладающую возможностями как контекстного, так и реляционного поиска. Russian
Context позволяет искать документы с учетом морфологии русского и английского
языков, используя SQL-подобный язык запросов и комбинируя поисковые ограничения
на контекст с ограничениями на заданные атрибуты документов. Продукт работает в
среде Windows.
Инструментарий разработчика
RCO Morphology. Продукт позволяет включить
русскую морфологию в системы информационного поиска. RCO Morphology
поддерживает все возможности морфологического анализа для известных и
неизвестных слов русского языка: определение грамматических характеристик
слова, приведение к нормальной форме, получение требуемых словоформ. Продукт
поставляется в виде динамической библиотеки (dll) для Windows.
RCO
Thesaurus Search Продукт позволяет включить тезаурус русского языка в информационно-поисковые
системы для повышения полноты поиска. Тезаурус общей лексики содержит более 75 тысяч
слов и словосочетаний, связанных отношениями синонимии и общее-частное, а также
словарь семантически малозначимой лексики (стоп-слова). Продукт предназначен
для расширения запросов к тексту близкими по смыслу словами, а также для
отождествления близких по смыслу цепок слов и их приведения к единому виду.
Продукт
поставляется в виде динамической библиотеки (dll) для Windows.
RCO
Syntactic Engine Продукт позволяет включить возможности синтактико-семантического анализа
русского текста в интеллектуальные информационные системы, требующие работы со
смыслом документа. RCO Syntactic Engine позволяет решать задачи, требующие
выявления скрытых взаимосвязей между целевыми объектами (персоналиями,
организациями, событиями) и семантической классификации отношений между ними на
основе автоматического анализа текста.
Продукт
поставляется в виде динамической библиотеки (dll) для Windows.
![]()
RCO Semantic Network . Продукт предназначен для разработчиков
информационно-поисковых и аналитических систем и позволяет выявить ключевые
понятия документа, в том числе наименования персон и организаций, с
ассоциативными связями между ними на основе грамматического и статистического
анализа текста, а также получить несколько видов рефератов документа. Область
применения RCO Semantic Network охватывает задачи построения информационного
портрета документа, тематического индексирования полнотекстовых баз данных,
сбора информации о целевых объектах (персонах и организациях).
Продукт поставляется в виде динамической библиотеки (dll) для Windows и разделяемой библиотеки (shared library) для Linux.
RCO Pattern
Extractor Продукт предназначен для анализа текста и
распознавания в нем различных объектов в соответствии с образцами, заданными на
формальном языке. Область применения RCO Pattern Extractor в первую очередь
включает в себя выделение сложных элементов текста и специальных конструкций,
отличающихся особого вида написанием, – различных наименований, адресов,
номеров и т.п.
Продукт поставляется в виде динамической библиотеки (dll) для Windows.
В комплект поставки продукта входит стандартный набор образцов для выделения нескольких
классов объектов - наименований физических и юридических лиц, дат, составных
географических названий и ряда других объектов. Пользователю предоставляются
возможности настройки стандартных образцов и введения своих собственных,
описывающих интересующие объекты.
RCO TopTree
Продукт предназначен для автоматической
классификации и построения иерархических рубрикаторов по заданному множеству
произвольных объектов, характеризуемых набором атрибутов. Как объекты, так и их
атрибуты при анализе представляются целочисленными идентификаторами, поэтому их
семантика не имеет значения для работы библиотеки.
В сочетании со средствами автоматического анализа текста, позволяющими выделять
семантические атрибуты, продукт может использоваться при решении задач экспресс-анализа
и автоматической маршрутизации потоков документов.
Продукт поставляется в
виде динамической библиотеки (dll) для Windows.
![]() Инструментарий аналитика
Инструментарий аналитика
RCO КАОТ . Информационно-аналитическая система для
работы в локальной сети на базе MS Windows и MS Internet Information Server,
которая реализует комплекс функций интеллектуального анализа и поиска текстовой
информации с поддержкой Web-интерфейса пользователя.
Продукт представляет базовое решение для организации автоматизированного
рабочего места аналитика и включает в себя передовые технологии обработки
текста, лингвистические и математические алгоритмы. Эти средства могут быть
использованы для решения широкого класса задач: от контекстного поиска
документов с учетом всех словоформ, синонимов и опечаток до поддержки принятия
экспертных решений на основе анализа информационных массивов с применением
искусственного интеллекта.
В состав RCO
КАОТ входит набор программных модулей, часть из которых может поставляться или
адаптироваться к нуждам заказчика независимо от других.
RCO Fact
Extractor – это
персональное приложение для Windows, которое предназначено для аналитической
обработки текста на русском языке и выявления фактов различного типа, связанных
с заданными объектами – персонами и организациями. Основная сфера применения
программы – это задачи из области компьютерной разведки, требующие
высокоточного поиска информации, например, автоматический подбор материала к
досье на целевой объект или же мониторинг определенных сторон его активности,
освещаемых в СМИ. Программа позволяет не только найти фрагменты текста, в
которых говорилось, например, о поездках персоны, ее встречах, заключении
договоров, сделках купли-продажи, но и точно определить все места поездок,
визави и контрагентов, наименование товаров и прочее.
Столь полное перечисление
продуктов Oracle дано с целью возможного использования отдельных компонент для обработки
русских (и английских) текстов.
Наиболее интересна последняя программа - Fact Extractor, воплотившая в себе наиболее продвинутые решения из области компьютерной лингвистики и искусственного интеллекта, разработанные в компании “Гарант-Парк-Интернет”[2].
Программа работает в среде Windows 2000 и выше и позволяет обрабатывать документы в популярных текстовых форматах из различных источников - файловой системы, заданных web-сайтов, базы данных.
Результат работы программы – таблица, которая содержит информацию о найденных фактах, связанных с объектами мониторинга, и может экспортироваться в html-формат для формирования отчета или для загрузки в стороннее приложение, работающее с уже структурированными данными.
Fact Extractor предполагает настройку шаблонов для поиска и классификации фактов самых различных типов. Такие специализированные шаблоны либо приобретаются отдельно, либо создаются пользователем самостоятельно при помощи дополнительной программы Fact Tuner. Тем не менее, даже стандартные шаблоны, включенные в комплект поставки Fact Extractor, позволяют распознавать огромное количество самых разнообразных фактов, но без детальной классификации, т.е., попросту находить события, в которых участвует целевой объект, и извлекать из текста всех прочих фигурантов этих событий, без детализации их ролей.
С учетом уникальных механизмов выделения и отождествления различных обозначений объектов в тексте, даже эти стандартные возможности делают Fact Extractor весьма полезным поисковым инструментом в тех случаях, когда поиск ведется по персонам и организациям. Помимо собственно программы с графическим интерфейсом для Windows, компания “Гарант-Парк-Интернет” выпускает пакет для разработки программного обеспечения (SDK), на базе которого построен Fact Extractor и который позволяет включать возможности анализа текста в собственные приложения.
3.2. Продукты Convera
ООО «Convera» - российская компания, представляющая в
России и странах СНГ интересы американской корпорации Convera Technologies
International (ранее Excalibur). Семейство продуктов фирмы Excalibur Technologies
(США) - лидер архивных систем 3 и 4 поколений. Ее продукты в течение
использовались Госдепартаментом и Национальной библиотекой Конгресса США
(крупнейшее в мире электронное хранилище), ЦРУ, компаниями Ford Motors,
Lockheed, Reynold Electrical&Engineering, Maine Yankee Atomic Power, а в
России — ФАПСИ РФ, Конституционным
судом РФ, ВНИИ ГПЭ и рядом ведущих российских банков [3].
Такой широкий спектр разнообразных внедрений во многом определяется как уникальным механизмом нечеткого поиска, так и широкими возможностями создания собственных приложений, основанных на базовой технологии. Основу математического описания поискового механизма составляет так называемая нейронная сеть, позволяющая выделять в зашумленной битовой последовательности похожие фрагменты, не требуя точного контекстного совпадения запроса и фрагмента в документе.
Поиск ведется с привлечением семантической сети, ориентированной на использование лингвистических ресурсов языка. Для русского языка выделено два сильно связанных компонента.
Во-первых, это модуль морфологического анализа, преобразующий слова к их нормальным формам (для существительных — именительный падеж единственного числа, для глаголов неопределенная форма и т. п.). Фактически при этом задаются слова языка с различными вариантами написания и перечнем смысловых значений.
Во-вторых — тезаурус (словарь), устанавливающий связи между различными значениями слов с указанием типа и силы связи.
|
Уровни семантического расширения слов |
«Сила связи» |
Пример |
|
Слово-оригинал |
1.00 |
Легкий |
|
Точно совпадающие слова и морфологические варианты |
1.00 |
Легкий, легкие, легок |
|
Варианты написаний и неправильные формы слов |
0.84 |
Легкий |
|
Производные слова |
0.74 |
Легкость, облегчение, полегчать |
|
Строгие синонимы |
0.62 |
Элементарный, простой, нехитрый |
|
Синонимы |
0.55 |
Невесомый, пустяковый, эфемерный |
|
Строгие антонимы |
0.43 |
Тяжелый, увесистый, трудный, хитрый |
|
Антонимы |
0.27 |
Нетривиальный, непростой |
|
Связанные слова |
0.16 |
Весы, сложность |
|
Контрастные слова |
0.06 |
Нелегкий |
Был создан электронный тезаурус
(словарь) русского языка для более 40 тыс. общеупотребимых слов с необходимыми
связями. Теперь понятия «шли» и «идти» не стоят далеко друг от друга,
упорядоченные по алфавиту, а связаны как близкие, и по ним возможен нормальный
поиск. Разработаны и инструментальные средства для пополнения и дальнейшего
развития тезауруса. Convera
расширяет и развивает решения, заложенные в Excalibur [4].
В числе отличительных
особенностей решений Convera:
- возможность находить нужную информацию с помощью
«нечеткого» и ассоциативного поиска (используются технологии адаптивного
распознавания образов и представления предметной области в виде связанной
семантической сети);
- функции кросс-языкового поиска и динамической рубрикации
всей поступающей информации;
- высокая степень масштабируемости, обеспечивающая
аналитическую обработку десятков терабайт информации в
территориально-распределенной среде.
Создавая единое поисковое
пространство для организации с предоставлением богатого инструментария по
развитию системы, продукты Convera могут быть использованы для решения целого
ряда смежных задач. Например, в качестве программной платформы для проведения
конкурентной разведки, мониторинга СМИ и оценки маркетинговой активности
компании, проведения фоновой оценки компетенций персонала и пр.
Обеспечивая поиск, извлечение и
анализ огромных массивов как неструктурированных, так и формализованных данных,
решения Convera создают мощную и надежную платформу для построения корпоративной
системы управления знаниями. Продукты Convera «работают» не только с текстовой,
но и с мультимедийной информацией (видео, звук, графика и пр.), представленной
более чем в 250 форматах. Они позволяют осуществлять поиск данных по всему
многообразию корпоративных и внешних источников: в файловых системах, СУБД,
корпоративных почтовых и информационных системах, системах электронного документооборота,
а также в удаленных хранилищах данных, сети Интернет и пр.
3.3. Система ConExT
ConExt – система автоматизированного извлечения знаний из
текстов на естественном языке.
Компания «НооЛаб», Новосибирск, Россия [5], [6].
ConExT - система автоматизированного извлечения
знаний из текстов на естественном языке. Целью создания системы является
решение следующей задачи: помочь пользователю в получении знаний из больших
массивов текстовых документов без необходимости прочитывать их все.
При
подаче на вход текстов на естественном языке (в стиле "деловая
проза"), система способна реконструировать содержание и выделить имеющиеся
в тексте знания, которые могут быть представлены пользователю в виде компактных
отчетов (схем, рефератов), или направлены в базу знаний.
Новацией
предложенной и экспериментально проверенной модели является метод выделения из
текста содержательно-значащих единиц, их отвлечения от грамматической формы и
перехода к моделям содержания. Метод реализуется за счет взгляда на текст через
призму модельных представлений двух типов:
А) правила, традиции и
феномены выражения мыслей в текстах на русском языке;
Б) инвариантный к
языку ограниченный набор категорий, использующихся
при выражении подавляющего большинства знаний о мире (объектах, субъектах,
процессах, явлениях, отношениях и т.п.).
Важной
составляющей системы является язык программирования tExp, специально созданный
для решения задач структурного анализа неформализованных текстов на
естественном языке. Наличие языка программирования tExp позволяет гибко подстраивать
систему под особенности выражения содержания в различных прикладных областях.
Ядро ConExT включает в себя:
- декларативный язык
программирования высокого уровня tExp,
специально предназначенный для
создания программ синтаксической и семантической обработки текстов на
естественном языке;
- словарь русского языка Ru-Dict (на основе
синтаксического словаря Зализняка);
- прикладные программы синтаксического
анализа текста и перевода его в нормативные
лингвистические Е5-структуры;
- прикладные программы категориального
анализа, реконструирующие содержание -
объекты, описанные в тексте;
- принципы и методики спецификации прикладных
программ под конкретные приложения.
Итогом
лингвистического анализа является перевод простых предложений (и др.
лингвистических единиц) в единую "каноническую" форму Е-5 структуры.
Е-5 структура содержит в себе пять элементов (тематические объект и предикат,
связка, рематические объект и предикат) и играет роль обобщенной пропозициональной
модели.
Для
каждой лингвистической единицы строятся модели возможных объектов содержания.
Синтез отдельных объектов в единую систему осуществляется за счет
конструктивных моделей, таких, например, как "акт коммуникации",
"досье субъекта рынка", "отраслевая цепочка",
"событие", "технология публичной политики", "передел
собственности" и др.
Системы знаний:
знаниями считаются
структуры связанных между собой знаковой формы и объективного содержания; под
знаковой формой понимаются тексты или фрагменты текстов (упорядоченные по дате,
источнику, автору), а под содержанием - модели объектов, описанных в тексте
(компании, персоны, связи между ними, события и др.) и характеристики ракурса,
с которого автор текста описывает объекты.
Переработка текстов в данные и знания может быть специфицирована запросами пользователя:
- за счет введения запроса в виде ключевых слов или развернутого текста на естественном языке;
-
за счет
настроек - подключения специализированных словарей, категориальных и
понятийных шаблонов, являющихся
компонентами CONEXT
Главные
функциональные элементы CONEXT.
1. Предсинтаксический анализ текста
2. Выделение и анализ метатекста
3.
Извлечение из текста данных с помощью простых шаблонов
4. Выделение основных лексических единиц: простых предложений, причастных и деепричастных оборотов.
5.
Факторизация предложения
6. Определение синтаксического типа предложения
7. Синтаксический Е5-анализ
предложений
8. Дефакторизация предложения (развертывание предложения в его исходный
целостный сложный вид )
9. Определение групп подлежащего и сказуемого
10.
Анализ модального содержания
11.
Категориальный анализ
12.
Анализ коммуникативного содержания
13.
Понятийный синтез и извлечение из текста знаний
14.
Отличие от аналогов - принцип диспараллелизма формы и содержания, реализованный в CONEXT.
Ближайшим аналогом CONEXT является технология RCO компании Гарант-Парк-Метрикс. На основе открытой информации можно
заключить, что в RCO реализуется традиционный для формальной логики и семиотики принцип параллелизма формы и содержания
знаний.
Принцип параллелизма был подвергнут фундаментальной критике в работах по
основаниям логики (Г.П.Щедровицкий, Н.Г.Алексеев).
При реконструкции сложного системного содержания (например "передел
собственности", "отраслевая цепочка стоимости" и т.п.) можно
ожидать, что ограничения, накладываемые этим подходом, станут принципиальными.
В CONEXT реализована идея диспараллелизма, лежащая в основе содержательно-генетической
логики (Г.П.Щедровицикий,
Н.Г.Алексеев, И.С.Ладенко). Это является принципиальным
"ноу-хау" технологии, открывающим широкие возможности для
восстановления по рассеянной текстовой информации реальных сложных системных
объектов.
15. tExp - модели и алгоритмы CONEXT реализованы на специально созданном языке программирования tExp
ВОЗМОЖНОЕ ИСПОЛЬЗОВАНИЕ ConExT
Текст - базы данных
(T2DB)
До
недавнего времени информационные технологии "добычи данных" (data
mining) позволяли автоматически заполнять базы данных только числовой, или
специально формализованной и стандартизированной текстовой информацией.
ConExT создает принципиально новую возможность -
автоматически заполнять БД информацией из неформализованных текстов на
естественном языке. Предполагается использовать мощные и отработанные
технологии различных СУБД в новой области - для поиска и аналитической обработки
больших массивов текстов (анкет, новостей, аналитических обзоров, объявлений,
материалов из СМИ и т.д.).
ConExT позволяет обрабатывать тексты жанра деловой
прозы, извлеченные пользователем из интернета/интранета или любых других
хранилищ информации. Технология обеспечивает автоматическое выделение из
текстов простых сведений об объектах, таких как
·
товары и цены,
·
компании и их
атрибуты, адрес, телефон, электронная почта и т.д.
·
персоны, их
должности, адресе и т.д.,
·
географические
названия,
·
даты и
временные характеристики событий,
Выделенные сведения
заносятся в базы данных.
ЕЯ интерфейс: запросы
на естественном языке к базам данных
ConExT позволяет создать удобный для непрофессионального
пользователя интерфейс между человеком и базой данных. Человек вводит запросы в
произвольной форме на естественном языке, а ConExT автоматически
"понимает" содержание запроса и переводит его в формальный запрос к
базе данных.
Примеры запросов:
·
Есть ли
мобильники Sony дешевле $200?
·
Книги, журналы,
изданные позже
·
Что сказал
господин Иванов про господина Петрова в интервью?
·
Кто упомянут в
последних новостях в связи с выборами мэра города?
Эта функция ConExT
может найти применение во всех случаях, когда человеку нужно сделать запрос по
смыслу дела, и легче всего выразить этот смысл в обычной речевой фразе.
С
помощью ConExT электронный магазин сможет предоставить клиентам уникальный
сервис. Покупатель может запрашивать информацию в произвольной форме, по смыслу
дела, и при этом поиск товаров будет эффективным - легким, удобным и точным.
Пояснение на
примере торговли книгами.
Зачастую покупатель не помнит имени автора, точного названия книги, но достаточно хорошо представляет себе, какое именно содержание его интересует. Если бы у покупателя была возможность посоветоваться с консультантом-библиографом, он, несомненно, нашел бы нужную книгу и сделал покупку. Дело в том, что консультант знает книги не только по их названиям, но и по их содержанию, хотя бы на уровне аннотаций.
ConExT позволяет заместить человека-консультанта
интеллектуальной компьютерной технологией. За счет обработки аннотации с
помощью ConExT, для каждой книги может быть сформирована своя модель
содержания книги. Эти модели хранятся в БД, связанной с каталогом. Поиск
является эффективным потому, что запрос пользователя соотносится с
содержательными характеристиками книг.
Создатели ConExT описывают направление перспективных разработок, связывая
его с новым типом систем аналитики и информационной разведки.
Постановка проблемы
Часто
для принятия решения деловому человеку, финансисту или политику нужно иметь
точное знание о некоторой ситуации: вокруг каких ресурсов идет борьба? кто
участники? как между собой они связаны? как начнут развертываться события во
времени?
Но
если исходных сведений недостаточно, необходима исчерпывающая информация.
Обычно информацию собирают из дополняющих друг друга источников: от друзей, из
прессы, из телевизионных передач: Важнейший информационный канал - Интернет.
Профессиональная работа современного делового человека немыслима без
использования ресурсов электронной сети. В Интернете собираются сведения из печатных
изданий, независимых аналитических центров, информационных агентств. Эта
информация накапливается в информационных узлах - крупных порталах.
Безусловно,
Интернет - уникальное хранилище информации. Однако реальность такова, что
каждый из источников высвечивает только некоторую часть ситуации и с некоторой
частной точки зрения. Информация о единой ситуации оказывается рассыпана и
трудно интегрируемой. Мало того, что нужная информация разрозненна, рассредоточена
в массе различных текстов. Она еще и зашумлена тысячами других сведений.
Обычно
аналитику приходится проделывать большую и тяжелую работу. С помощью поисковых
систем "Яндекс", "Рамблер" и др. раскапывать документы.
Вручную отсеивать "мусор" - похожие, но не относящиеся к делу тексты.
Выискивать нужные сведения и приводить их в систему, чтобы уяснить целостную
картину события. Это стоит многих времени и сил. При этом важные косвенные и
неявные связи, слабые сигналы развития событий при подобной технологии зачастую
просто недоступны и остаются "невидимыми".
НооЛаб
предлагает переход от информационных к технологиям знаний, при этом важнейшим
элементом технологий знаний должны стать механизмы реконструкции содержания
текстов (ConExT). Примером реализации нового подхода является программный
комплекс РАСПАС, инициативную разработку которого компания НооЛаб ведет с осени
РАСПАС
должен стать принципиально новым инструментом информационной разведки и
аналитики, знаниевого оснащение управленческих мышления и деятельности.
В
отличие от, скажем, "Яндекса", в РАСПАС предполагается осуществлять
поиск документов не по ключевым словам, а по содержанию. РАСПАС должен
реконструировать содержание текстов - кто? с кем? по поводу чего? когда? где?
При этом по многим различным документам в базе знаний должна воссоздаваться
единая структурная модель ситуации.
Используя РАСПАС, предполагается получать:
·
сведения о
полном составе участников и действующих лиц ситуации;
·
тексты их
высказываний о ситуации и друг о друге;
·
сведения о их
связях, характере действий, целях и т.д.;
·
знания о
временной динамике происходящих событий;
·
знания об
источниках, освещающих событие.
РАСПАС должен обеспечивать непрерывное информационное
отслеживание ситуации, построение прогнозов развития событий и их фактическую
проверку.
3.4. OntosMiner
Набор продуктов Ontos Series, разработан швейцарской компанией Ontos AG при активном участии российских ученых. Продукты Ontos решают две основные задачи: получение информации из различных гетерогенных источников (базы данных, Internet, поисковые машины, файловые серверы и т. д.) и ее последующая обработка с использованием оригинальных лингвистических алгоритмов [7].
Ontos позволяет не только взаимодействовать с файлами и базами данных различных форматов, но и обрабатывать содержимое документов с учетом их форматирования. В частности в документе различается основной текст, заголовки разделов, таблицы и т. д. Однако главной изюминкой продуктов Ontos является инновационный механизм OntosMiner* аналитической обработки текстов, основу которого составляет патентованная технология, относящаяся к классу NLP (Natural Language Processing -- обработка естественного языка).
OntosMiner разработан на основе продукта GATE (General Architecture
for Text Engineering),
который представляет собой SDK, распространяемый бесплатно по лицензии GNU
(Open Source) Шеффилдским университетом (Великобритания).
В отличие от
классической схемы обработка документов в OntosMiner изначально
осуществляется с учетом конкретной предметной области и возможных вариантов
анализа исходных материалов, что приводит к резкому сокращению анализируемых
комбинаций слов. При этом теряется
универсальность, однако опыт практического применения полнотекстовых баз данных
показывает, что основной объем информационных задач связан с выполнением
запросов вполне конкретного вида (в конце концов, режимы полнотекстового поиска
всегда можно применить к любым документам).
Второе важное новшество заключается в том, что между различными словами-существительными выявляются взаимосвязи качественно более высокого уровня, которые обычно описываются глагольными формами (иллюстрируется на примере). Как известно, при решении нечетких математических задач встречаются ошибки 1-го (обнаружение ложной цели) и 2-го (пропуск реальной цели) рода. Подобные ситуации возникают и при обработке текстов, простейший случай - выборка документов, не относящихся к теме запроса, или пропуск нужных документов.
При решении этой проблемы в NPL-технологии используется известный медицинский принцип "не навреди". В данном случае ошибки 1-го рода исключаются за счет того, что фрагменты текстов, не поддающиеся смысловой обработке, просто игнорируются. Конечно, такой подход резко повышает вероятность появления ошибки 2-го рода. Но тут следует учесть, что автоматическая обработка подразумевает анализ не одного, а сотен и тысяч документов.
Теория вероятности убедительно
показывает, что если в одном документе вероятность пропуска цели составляет
50%, то при комплексной обработке уже 10 документов она снижается до 0,1% (т.
е. в каждой из 10 попыток проверки гипотезы будет допущена ошибка).
Система использовалась в частности для анализа рапортов в предметной области "Угон автомобиля". В результате обработки формируется структурированный XML-образ документа, который может отображаться в виде сетевой диаграммы Cognitive Map (когнитивные карты) типа приведенной ниже.
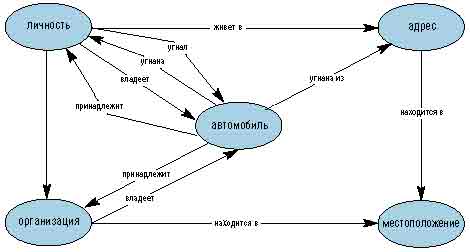
Имея такие формализованные модели, можно
достаточно просто выполнять самые различные запросы, определяя, например,
наиболее криминальные районы, самые любимые преступниками модели машин или
выявляя сложные взаимосвязи между разными персонами (для формирования подобных
запросов используются специальные графические инструменты).
Формирование словарей Ontology
В приведенном примере, использовались
документы определенного вида, хотя и заполненные в относительно произвольной
форме. На самом же деле в качестве исходных могут выступать самые различные
материалы.
Состав и структура извлекаемых данных все равно определяются конкретными словарями типа Ontology, которые являются специфическими для каждой предметной области (точнее, класса решаемых аналитических задач) и сильно зависят от национальных особенностей языка.
Для получения их пользователю предлагается три основных варианта. Первый - использовать готовые "вертикальные" решения. Они формируются разработчиками (специалистами компании Ontos и ее партнеров) для наиболее широких сегментов рынка. На сайте www.ontosearch.com уже есть целый набор словарей для различных сфер деятельности - политика, медицина, финансы, правда, в большинстве своем для английского и немецкого языков (словари поставляются в виде платного сервиса).
Второй вариант - заказать создание таких словарей для конкретных целей (именно так был реализован проект в МВД Киргизии). Третий - формировать их собственными силами.
В составе продуктов Ontos Series имеется также набор инструментов для создания и редактирования Ontology-словарей, в том числе с использованием простейших методов самообучения.
3.5. Язык OWL
3.5.1. Общие сведения
Проблему представления знаний (knowledge representation) в настоящее время
обычно именуют онтологией. Эта проблема интенсивно разрабатывается создателями Internet-стандартов, на переднем крае разработок в этой
сфере сейчас находится Семантическая
Сеть (Semantic Web, согласно терминологии W3C). По словам Тима Бернерс-Ли, «основателя»
WWW, Семантическая Сеть — развитие концепции существующей глобальной сети. С
целью описания и представления объектов в Семантической Сети создается язык OWL (Ontology Web Language),
разработку которого одобрил консорциум W3C[8]. В настоящее время
разработчикам Семантической Сети стало
очевидно, что средств XML и RDF для представления информации и метаданных для
построения полноценной семантически связанной сети недостаточно.
По мнению разработчиков OWL, поможет запустить автоматизированные инструменты для глобальной сети нового поколения, предлагая такие усовершенствованные услуги, как более точный Web-поиск, интеллектуальные программные агенты и управление знаниями.
Согласно принципам Семантической Сети, процесс создания электронных документов разбивается на две части: создание собственно документа, содержащего некоторые термины, и создание его онтологии. Язык OWL записывает онтологию на некотором языке (с естественно-языковой ориентаций уровня SQL) и в формате XML. Однако в основе OWL находится LBase — исключительно математический язык, который опирается на аппарат математической логики и предикатов, и предназначен для машинных низкоуровневых логических выводов.
Разработчики OWL ссылаются на язык логического программирования Пролог для вывода из фактов,
находящихся в базе знаний программы, новых фактов, опираясь на логические
теоремы. По сути OWL базируется на одной из модификаций
представления знаний с помощью формул исчисления предикатов. Язык OWL включает ряд интересных особенностей (логический вывод,
развитые средства работы с онтологиями, в частности с их версиями; поддержку
теоретико-множественных операций; организацию иерархий как классов, так и
свойств), однако вопрос о преодолении в реализациях языка недостатков, присущих
внутренним механизмам Пролога, остается открытым.
3.5.2.
Веб-онтологии OWL
По языку OWL в Интернет имеется достаточно подробная и постоянно модифицируемая документация [9]. Приведем некоторые фрагменты из перевода на русский язык исходной английской версии [10], дающие некоторое представление о стиле использования языка.
Язык OWL - это язык для определения и представления веб-онтологий. Веб-отнология может включать описания классов, свойств и их примеры. Формальная семантика OWL описывает, как получить логические следствия, имея такую онтологию, т.е. получить факты, которые не представлены в онтологии буквально, но следуют из ее семантики. Эти следствия могут быть основаны на одном документе или множестве распределенных документов, которые комбинируются с использованием определенных механизмов OWL.
Вопрос, который возникает, когда описываешь еще один
XML/Web стандарт, - это "Что это дает,
чего не могут дать XML и XML Schema?" Есть два ответа на этот вопрос.
- Онтология отличается от схемы XML тем, что это
представление знания, а не формат сообщений. Большинство веб-стандартов
состоят из комбинации форматов сообщений и спецификаций протоколов. Этим
форматам дали эксплуатационную семантику, типа, "По получении
сообщения ЗаказНаПокупку,
перевести Количество
рублей со СчетПокупателя
на СчетПродавца
и отпустить Товар."
Но спецификация не создана для поддержки операций вне контекста данной транзакции.
Например, у нас нет, как правило, механизма, чтобы заключить, что из-за
того, что Товар
имеет название Шардоне, он должен также быть белым вином.
- Одним из преимуществ OWL онтологий будет
доступность инструментов, которые могут рассуждать о них. Инструменты
обеспечат общую поддержку, которая не является специфической для
данной предметной области, что было бы тем случаем, когда надо построить
систему, чтобы рассуждать в пределах одной стандартной для данной
индустрии XML схеме. Построение четкой и работоспособной системы
рассуждения - непростое дело. Строительство онтологии намного более
доступно. Мы ожиданием, что много групп предпримут строительство
онтологий. Они извлекут выгоду из инструментов третьих лиц, основанных на
формальных свойствах языка OWL, инструментов, которые предоставят
ассортимент возможностей, которые большинству организаций было бы трудно
реализовать самим.
OWL обеспечивает три различных по выразительности диалекта,
спроектированных для использования отдельными сообществами разработчиков и
пользователей.
·
OWL Lite поддерживает тех пользователей, которые нуждаются, прежде всего,
в классификационной иерархии и простых ограничениях. Например, притом, что он
поддерживает ограничения кардинальности (количества элементов), допускаются
значения кардинальности только 0 или 1. Для разработчиков должно быть проще в
своих продуктах обеспечить поддержку OWL Lite, чем его более выразительных
собратьев, в частности, OWL Lite позволяет быструю миграцию тезаурусов и других
таксономий.
·
OWL DL поддерживает тех пользователей, которые хотят максимальной
выразительности без потери полноты вычислений (все заключения гарантировано
будут вычисляемыми), и разрешаемости рассудочных систем (все вычисления
завершатся в определенное время). OWL DL включает все языковые конструкции OWL
с ограничениями вроде разделения типа (класс не может быть частным свойством, а
свойство не может быть индивидом или классом). OWL DL так назван из-за его
соответствия дескриптивной логике [Дескриптивная
логика], дисциплине, в которой изучен именно разрешаемый фрагмент логики
первого порядка. OWL DL была спроектирована, чтобы поддержать существующий
сегмент бизнеса, занимающийся дескриптивной логикой, и иметь желательные вычислительные
свойства для систем рассуждения.
·
OWL Full предназначается для пользователей, которые хотят
максимальную выразительность и синтаксическую свободу RDF без вычислительных
гарантий. Например, в OWL Full класс может одновременно рассматриваться и как
совокупность индивидов, и с равным правом как индивид. Другое существенное отличие
от OWL DL в том, что owl:DatatypeProperty может
быть помечено как owl:InverseFunctionalProperty.
OWL Full позволяет такие онтологии, которые расширяют состав предопределенного
(RDF или OWL) словаря. Маловероятно, что какое-либо рассудочное программное
обеспечение будет в состоянии поддержать полную поддержку каждой особенности
OWL Full.
Каждый из этих диалектов - расширение его более простого
предшественника, и в том, что касается выразительных возможностей, и в том, что
касается возможностей производимых заключений. Поддерживаются следующие
отношения, но не наоборот.
- Каждая допустимая OWL Lite онтология - допустимая
OWL DL онтология.
- Каждая допустимая OWL DL онтология - допустимая OWL
Full онтология.
- Каждое правильное OWL Lite заключение - правильное
OWL DL заключение.
- Каждое правильное OWL DL заключение - правильное
OWL Full заключение.
Разработчики онтологий, использующие OWL, должны решить,
какой из диалектов лучше подходит к их задачам. Выбор между OWL Lite и OWL DL зависит
от степени того, насколько пользователям требуются более выразительные
конструкции, обеспечиваемые OWL DL. Приложения для OWL Lite будут иметь
желаемые вычислительные характеристики. Приложения для OWL DL, при том, что
имеют дело с разрешаемым диалектом, в самых тяжелых случаях будут связаны с
более высокой сложностью.
Выбор между OWL DL и OWL Full, главным образом, зависит от
степени того, насколько пользователям требуются средства мета-моделирования RDF
Схем (например, определяющие классы классов). При использовании OWL Full, по
сравнению с OWL DL, рассудочная поддержка менее предсказуема. Для дальнейшей
информации см. Семантика
OWL.
Пользователи, мигрирующие из RDF в OWL DL или OWL Lite
должны позаботиться о том, чтобы оригинальный RDF-документ выполнял
ограничения, наложенные OWL DL и OWL Lite. Детали этих ограничений объясняются
в Приложении
E Справки по OWL.
Когда мы представляем конструкции, которые разрешаются
только в OWL DL или OWL Full, они помечаются "[OWL DL]".
Нормативный синтаксис обмена OWL - RDF/XML. Заметьте, что
OWL был спроектирован с максимальной совместимостью с RDF и RDF Schema. Форматы
XML и RDF - часть стандарта OWL.
OWL предполагает открытость.
То есть, описания ресурсов не ограничены единственным файлом или темой. В то
время как класс C1 первоначально может быть
определен в онтологии O1, он может быть расширен в других онтологиях. Следствия
из этих дополнительных суждений о C1
являются монотонными. Новая информация не может опровергать предыдущую
информацию. Новая информация может быть противоречащей, но факты и следствия
могут только добавляться, и не могут удаляться.
Типичная OWL онтология начинается с объявления пространства
имен (namespace),
Способность OWL выражать онтологическую информацию об
индивидах, содержащихся во множестве документов, принципиальным образом
поддерживает связывание данных из разных источников. Лежащая в основе семантика
обеспечивает возможность делать выводы из этих данных, что может привести к
неожиданным результатам. В частности способность выражать эквивалентность с
помощью owl:sameAs может быть
использована, чтобы заявить, что как будто бы различные индивиды на самом деле
одно и то же. Owl:InverseFunctionalProperty
также может быть использовано, чтобы связать индивидов вместе.
Например, если такое свойство как "ИНН" является owl:InverseFunctionalProperty, то два отдельных человека могли бы быть расценены как
один и тот же на основе того, что они имеют одно и то же значение этого
свойства. Когда идентичность индивидов определяется такими средствами,
информация о них из разных источников может быть слита. Эта агрегация
может использоваться, чтобы определить факты, которые не представлены прямо
ни в одном из источников.
Способность Семантической Сети связывать информацию из
многих источников - желательное и мощное свойство, которое может использоваться
во многих приложениях.
Однако, способность объединять данные из многих источников в сочетании с мощью
логического вывода OWL, действительно имеет потенциал для злоупотребления.
Пользователи OWL должны быть заботиться о потенциальной угрозе секретности.
Детальные решения по защите информации были расценены как выходящие за область
рассмотрения данной рабочей группой. Множество организаций, занимающихся этими
вопросами, предлагает широкий спектр решений по безопасности и секретности.
Наиболее фундаментальные понятия в какой-то области должны
соответствовать классам, которые находятся в корне различных таксономических
деревьев. Каждый индивид в мире OWL является членом класса owl:Thing. Таким образом каждый определенный пользователем класс
автоматически является подклассом owl:Thing. Специфичные для данной области корневые классы
определяются простым объявлением именованного класса. OWL также определяет
пустой класс, owl:Nothing.
Фундаментальным таксономическим конструктором для классов
является rdfs:subClassOf. Он связывает
более частный класс с более общим классом. Если X - подкласс Y, то каждый
представитель X - также представитель Y. Отношение rdfs:subClassOf является транзитивным. Если X - подкласс Y, и Y - подкласс
Z, то X - подкласс Z.
Определение класса состоит из двух частей: указание названия или ссылка и список ограничений. Каждое из непосредственно содержащихся в определении класса выражений ограничивает (уточняет) свойства представителей определенного класса. Представители класса принадлежат к пересечению указанных ограничений.
В дополнение к классам мы хотим иметь возможность описать их
членов. Обычно мы думаем о них как об отдельных индивидах в нашем пространстве
вещей. Для определения индивида достаточно объявить его членом какого-то
класса.
Например:
<Регион rdf:ID="РегионЦентральногоПобережья" />
Есть пара моментов, на которых
здесь следует остановиться. Во-первых, мы решили, что РегионЦентральногоПобережья (определенная область) является членом Регион, класса, содержащего все географические регионы.
Во-вторых, нет никаких требований в примере из двух частей, что эти два элемента
должны следовать друг за другом, или даже находиться в одном и том же файле
(хотя, в противном случае их названия должны были бы быть расширены с помощью
URI). При проектировании веб-онтологий нужно помнить, что они предназначены для
распределенной среды. Они могут быть импортированы и расширены, создавая новые
производные онтологии.
Существуют проблемы относительно различия между классом
и индивидом в OWL. Класс - это просто название и совокупность свойств,
которые описывают набор индивидов. Индивиды - это члены этих наборов. Таким
образом, классы должны соответствовать естественно образованным наборам вещей в
рассматриваемой области, а индивиды должны соответствовать реальным объектам,
которые могут быть сгруппированы в эти классы.
При создании онтологий, это различие часто размывается в
двух направлениях:
- Уровни представления: В определенных
контекстах что-то, что очевидно является классом, может самостоятельно
считаться представителем чего-то еще. Например, в онтологии вина мы имеем
понятие Виноград,
которое призвано обозначать набор всех разновидностей винограда. ВиноградКабернеСовиньон
- пример представителя этого класса, поскольку он обозначает фактический
сорт винограда, называемого Каберне-Совиньон. Однако, ВиноградКабернеСовиньон
мог бы сам считаться классом, обозначающим набор всех реальных кустов винограда
Каберне-Совиньон.
- Подкласс или частный случай: Бывает очень
просто спутать отношения по типу представитель-класс с отношением по типу
подкласс-надкласс. Например, выбор сделать ВиноградКабернеСовиньон индивидом,
являющимся представителем класса Виноград, а не подклассом класса Виноград
может показаться чисто произвольным. Но это не произвольное решение. Класс
Виноград
обозначает набор всех сортов винограда, и поэтому любой подкласс Винограда
должен обозначать подмножество этих сортов. Таким образом,
ВиноградКабернеСовиньон должен считаться представителем
Винограда, и не подклассом. Ведь он не описывает подмножество сортов
винограда, он сам является сортом.
Свойства
позволяют нам утверждать общие факты о членах классов и особые факты об
индивидах. Свойство - это бинарное
отношение. Различают два типа свойств:
- свойства-значения, отношения между
представителями классов и RDF-литералами или типами данных, определяемых
XML Schema
- свойства-объекты,
отношения между представителями двух классов. Заметьте, что слово объект
в названии не связано с RDF-термином
Пример определения:
<owl:ObjectProperty rdf:ID="сделаноИзВинограда">
<rdfs:domain rdf:resource="#Вино"/>
<rdfs:range rdf:resource="#Виноград"/>
</owl:ObjectProperty>
В OWL последовательность элементов без явного указания оператора представляет собой неявное соединение. Свойство сделаноИзВинограда имеет домен Вино и диапазон Виноград. Таким образом, это связывает представителей класса Вино с представителями класса Виноград. Множественные домены означают, что доменом свойства служит пересечение указанных классов (и подобным образом для диапазона).
Использование информации о диапазоне и домене в OWL отличается от информации о типе данных в языках программирования. В частности, в языках программирования типы данных используются, чтобы отслеживать взаимоувязанность кода. В OWL диапазон значений может использоваться, чтобы наследовать тип.
Свойства, так же как классы, могут быть организованы в
иерархию.
Мы отличаем свойства по тому, связывают ли они индивидов с
индивидами (свойства-объекты) или индивидов с типами данных
(свойства-значения). Свойства-значения могут иметь диапазон литералов RDF или
простых типов, определенных в XML
Schema datatypes.
OWL использует большинство встроенных типов XML Schema.
Ссылки на эти типы осуществляются посредством URI для типов http://www.w3.org/2001/XMLSchema. В документации перечислены более 30 типов данных, рекомендуемых
для использования с OWL. Другие встроенные типы XML Schema могут использоваться
в OWL Full, но с предостережениями, описанными в документе Семантика
и абстрактный синтаксис OWL.
Картирование
онтологий
Для того, чтобы онтологии имели максимальный эффект, они
должны быть широко распространены. А чтобы минимизировать интеллектуальные
усилия, затрачиваемые на разработку онтологий, они должны быть пригодными для
многократного использования. В лучшем из всех возможных варианте они должны
быть составлены из компонентов. Например, Вы могли бы воспользоваться
онтологией даты из одного источника и онтологией физического местоположения из
другого, и затем расширить понятие местоположения, включив в него период
времени, в течение которого данное местоположение сохраняется.
Важно понять, что большая часть усилий по разработке онтологии
посвящена связыванию вместе классов и свойств так, чтобы максимально точно
передать заложенный в понятия смысл. Мы хотим, чтобы простые утверждения о
членстве в классе имели широкие и полезные последствия. Это - самая сложная
часть разработки онтологии. Если Вы можете найти существующую онтологию,
которая уже широко используется и хорошо проработана, то имеет смысл
приспособить ее для своих нужд.
Чтобы связать вместе ряд онтологий, входящих в качестве
компонентов в какую-то третью онтологию, часто полезно иметь возможность
указать, что данные класс или свойство в одной онтологии эквивалентны классу
или свойство во второй онтологии. Эта способность должна использоваться с
осторожностью. Если объединенные онтологии являются противоречащими (все А - это
Б, в другой все А - это не Б), то не будет никакого расширения (ни индивидов,
ни отношений), который удовлетворяли бы получающуюся комбинацию.
В OWL нет допущения об уникальном имени. То, что
два имени отличны друг от друга, не означает, что они обозначают различных
индивидов. Объявление идентичными двух индивидов выполняется с помощью sameAs, а для указания явного
различия - с помощью differentFrom.
Для формирования классов OWL обеспечивает дополнительные
конструкции. Эти конструкции могут использоваться для создания так называемых выражений
класса. OWL поддерживает основные операторы множеств, а именно объединение,
пересечение и дополнение. Они называются, соответственно, owl:unionOf, owl:intersectionOf и owl:complementOf. Дополнительно
классы могут быть перечисленными. Расширения класса могут быть
заявлены явно посредством конструктора oneOf. И можно утверждать, что расширения класса должны быть
непересекающимися.
OWL обеспечивает средства определения класса через прямое
перечисление его членов. Это делается с помощью конструкции oneOf.
Замечательно, что это определение полностью определяет диапазон класса, так,
что никакие другие индивиды не могут быть объявлены как принадлежащие к данному
классу.
Непересекаемость набора классов может быть выражена с
помощью конструкции owl:disjointWith. Это
гарантирует, что индивид, который является членом одного класса, не может
одновременно быть представителем обозначенного другого класса.
Онтологии,
подобно программному обеспечению, требуют технической поддержки и, таким образом,
изменяются со временем. В пределах элемента owl:Ontology можно указать ссылку на предыдущую версию онтологии. Для
обеспечения этой связи предназначено свойство owl:priorVersion, которое может использоваться, чтобы проследить историю
версий онтологии.
Версии
онтологий могут быть несовместимыми друг с другом. Например, предыдущая версия
онтологии может содержать утверждения, которые противоречат текущей версии. В
пределах элемента owl:Ontology, мы используем
тэги owl:backwardCompatibleWith и
owl:incompatibleWith, чтобы указать на совместимость или ее отсутствие с
предыдущими версиями данной онтологии. Если owl:backwardCompatibleWith не объявлен, то совместимость не должна предполагаться. Кроме
того, owl:versionInfo обеспечивает
средства, пригодные для использования системами отслеживания версий. В
противоположность предыдущим трем тэгам, типом данных owl:versionInfo является литерал, и этот тэг может использоваться, чтобы
аннотировать классы и свойства в дополнение к онтологиям.
OWL
Full обеспечивает экспрессивную мощь для того, чтобы сделать утверждения любого
вида о классе, то есть, что это он является представителем другого класса, или
что он (а не его представители) имеет свойство и значение для этого свойства.
Эта структура может использоваться, чтобы построить онтологию классов и свойств
для отслеживания информации о версиях. OWL namespace включает два предопределенных
класса, которые могут использоваться для этих целей: owl:DeprecatedClass и owl:DeprecatedProperty. Они предназначены для указания того, что класс или
свойство вероятно будут изменены несовместимым образом в предстоящем выпуске.
Важно отметить, что owl:DeprecatedClass и owl:DeprecatedProperty не имеют никакой дополнительной семантики, и то, что они
используются по предназначению - целиком на совести разработчиков и пользователей
OWL.
В дополнение к языкам онтологий, различные таксономии и
существующие онтологии уже находятся в коммерческом использовании. В сайтах
электронной коммерции они облегчают коммуникацию посредством компьютера между
покупателем и продавцом, делают возможной вертикальную интеграцию рынков и позволяют
описаниям многократно использоваться на различных рынках. Примеры сайтов,
которые фактически создают онтологии для коммерческого использования, можно
найти в Интернет.
Разработаны различные медицинские или фармацевтические
онтологии, чтобы помочь управлять огромной массой данных современных медицинских
и биохимических исследований, которые бывает трудно связать вместе в единое
целое. Один из главных ресурсов Консорциум
Генных Онтологий.
Сегодня находятся в использовании большие таксономии,
которое были бы готовы для внедрения в OWL-пространство. Например,
Североамериканская Система Классификации Промышленности (NAICS) определяет
иерархию из более чем 1900 элементов, которые идентифицируют типы
промышленности. NAICS также связана с Международной Системой Классификации
Индустриальных Стандартов (ISIC, Ревизия 3), разработанной и поддерживаемой
Организацией Объединенных Наций.
3.6. Медиалогия
Медиалогия on-line система анализа информации из открытых источников: газет, журналов, информационных агентств, интернет-ресурсов, радио и телевидения. Система ориентирована на задачи управления бизнесом и по-видимому использует комбинированный подход, используя как алгоритмы обработки текста, так и когнитивные методы [11].
Система ежедневно структурирует, оценивает и семантически обрабатывает десятки тысяч сообщений из центральных, региональных и специализированных русскоязычных изданий, а также материалы ведущей иностранной прессы. В числе решаемых в системе Медиалогия задач - конкурентный анализ, информационная разведка, управление репутацией, изучение отраслевого рынка, оперативный мониторинг, просмотр новостей после выхода в эфир и другие.
В основе методики системы лежит классический компьютерный
анализ текста, который базируется на представлении содержания документа в форме
семантической сети ключевых понятий, ассоциативно связанных между собой.
Семантическая сеть реализуется с помощью Java
Applet. В качестве основы для пользовательского интерфейса и для
клиентов-операторов используется платформа Microsoft.NET.
Архитектура базируется на
платформе Windows 2000 Server. В каждой подсистеме своя кластерная часть,
которая поддерживает работу сервера баз данных Microsoft SQL Server 2000 и
сервера приложений Internet Information Server. В системе «Медиалогия»
используется несколько специальных решений для обеспечения безопасности,
визуализации данных и для поиска информации. В качестве сервера приложения используется
Microsoft Information Server. Обмен данными между подсистемами осуществляется в
формате XML.
Полнотекстовое индексирование Microsoft SQL Server 2000 реализовано с использованием RCO Morphology – библиотеки морфологического анализа текста компании «Гарант Парк Интернет». RCO Morphology дополняет технологию полнотекстового поиска по массивам документов Microsoft full-text Search компонентами, отвечающими за учет морфологии русского языка при построении индексов и обработке поисковых запросов;
Стиль работы с системой
иллюстрируют фрагменты видеоролика, приведенные на рис. 1, 2 и 3. Выбрав ряд
параметров, аналогично выбору финансовых отношений Аэрофлота на рис.1,
пользователь получает фрагмент семантической сети (граф отношений) – рис. 2.
Выбрав далее узел по нужному отношению, пользователь получает отчет, в котором
интересующие его объекты маркированы – рис. 3.
Рис. 1. Ввод параметров для получения семантической карты.
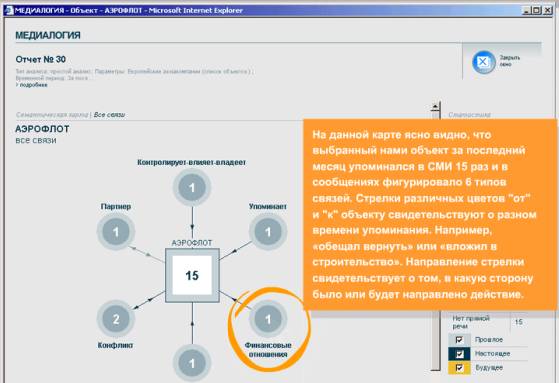
Рис. 2. Семантическая карта.
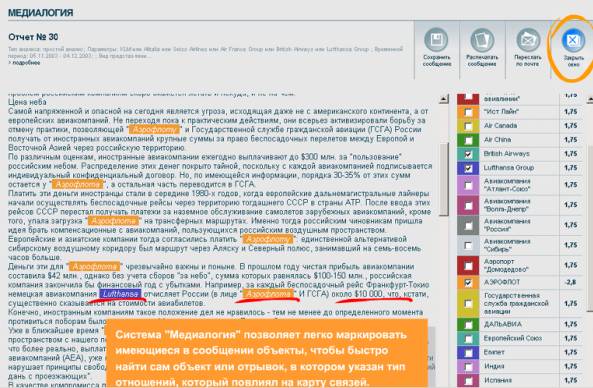
Рис. 3. Отчет по выбранному узлу семантической карты.
3.7. Программа Starlight 3.0
Зарубежные проекты и системы декларирует учет при обработке текстов лингвистических атрибутов и глубинной семантики, однако для русского языка эти системы требуют существенной модификации. Для оценки уровня разработок приведем пример системы Starlight 3.0 (разработанной в лаборатории PNNL), взятой на вооружение Министерством внутренней безопасности США[12].
Эта новая программная система, предназначена для поиска в интернете свидетельств террористической деятельности. Система Starlight 3.0 была разработана Тихоокеанской северо-западной национальной лабораторией (PNNL) по заказу силового ведомства США.Она представляет собой аналитическое средство, извлекающее из обильного почтового и веб-трафика информацию о связях между людьми, населенными пунктами и событиями. Внедрение программа Starlight 3.0 предполагалось в сентябре 2005 года. На основе проанализированных данных она должна выстраивать наглядные графические связи между объектами, описанными в многочисленных текстовых документах, а также изображениях, аудио- и видеозаписях.
Отслеживанием сетевой активности, прослушиванием телефонных разговоров и анализом открытых и конфиденциальных финансовых транзакций федеральные правоохранительные органы США занимаются давно. Полученные силовиками данные заносятся в гигантские информационные хранилища. Но программа, которая использовалась федеральными службами до сих пор, не обеспечивала наглядной визуализации связей. Новый графический интерфейс Starlight 3.0 позволит проводить интерактивный анализ базы данных, отсеивать нерелевантную информацию и поможет эффективно интегрировать поступающие новые потоки данных в существующее хранилище.
Система Starlight 3.0 способна анализировать одновременно до 40000 документов, в то время как предыдущая версия программы обрабатывала лишь 10000 документов. Кроме того, Starlight 3.0 обеспечивает одновременную визуализацию нескольких аналитических процессов, в том числе работающих с геоинформационными источниками данных. Благодаря этому наблюдатель сможет как определить временные и пространственные характеристики нескольких событий, так и их связи с другими важными событиями. Starlight работает в среде Windows и использует формат XML.
В настоящее время в лаборатории PNNL ведутся работы по совершенствованию еще одной программы - IN-SPIRE. Она способна извлекать осмысленные знания из больших массивов данных (включая тексты на нескольких естественных языках). Аналитические средства этой программы позволяют проверять различные гипотезы с помощью построения сложных моделей. Аналогичные системы используют и другие ведомства, в частности в Министерстве обороны функционирует система IxReveal. Система извлекает знания из больших текстовых массивов и позволяет отвечать на сложные вопросы.
3.8. UIMA(IBM)
Системе UIMA, разработанной IBM, уделено относительно больше внимания в силу двух привлекательных факторов: открытые тексты (в настоящий момент на JAVA, в дальнейшем предполагается доступность на платформе C++ ) и достаточно подробная документация. Документация содержит как описание концепций системы, так и технику работы с программными интерфейсами (примеры построения анализаторов). К сожалению в текущей версии эти анализаторы существенно ориентированы на английский язык, а создание анализаторов для русского языка (даже при наличии исходных текстов аналогичных анализаторов для английского) - требует специальной научной компетенции.
3.8.1. Общие сведения
Практическое отсутствие документации по UIMA на русском языке затрудняет адекватный перевод терминов, поэтому далее часто будет даваться ссылка (обычно в круглых скобках) на термин в исходном документе[15]. Перевод в основном выполнялся по возможности ближе к тексту оригинала. В процессе анализа неструктурированного (текстового) содержания в UIMA используются различные технологии анализа, включающие:
- обработка естественного языка с использованием статистики и правил(шаблонов);
- извлечение информации (Information Retrieval - IR);
- машинное обучение (Machine learning);
- онтологии (Ontologies);
- автоматический вывод (Automated reasoning);
- источники знаний (Knowledge Sources - WordNet, FrameNet, etc.).
При
анализе используется термин “span”
(спан, кусок, фрагмент) для выделения сплошного отрезка текста, обозначающее
некоторое целостное понятие. Фрагмент характеризуется начальной и конечной позицией и указанием на понятие, которое он
обозначает. Например, фрагмент “Fred Centers” от позиции 101 до 112 в некотором документе может
обозначать организацию (в исходном тексте “лицо” - The span from position
101 to
Результаты анализа (в частности аннотаторы) организуются в так называемую Общую Аналитическую Структуру (Common Analysis Structure (CAS)), в дальнейшем обозначаемую CAS-структура или просто CAS. Эта объектно-ориентированная структура позволяет представить объекты, свойства и значения. UIMA допускает вхождение объекта более чем в одну иерархию. UIMA предоставляет возможность включать в CAS не только базовые типы, но и их произвольное расширение, описываемое в Системе Типов (Type System). В первом приближении можно считать, что Система Типов это схема объекта в СAS.
Система типов описывает объекты,
которые могут быть обнаружены в документах и
записаны в CAS. Типы
могут иметь свойства (properties or features),
например “Age” и “Occupation” могут описывать свойства типа “Person”. Примеры других возможных типов: организация, компания, банк, Ссуда, Деньги, Размер, Цена, Телефонный Номер, Обращение по
телефону, Отношение, Сетевой пакет, Изделие, Группа Существительного, Глагол,
Цвет, Узел парсинга(разбора), Массив весовых свойств (Organization, Company, Bank, Facility, Money, Size, Price, Phone Number, Phone Call, Relation, Network Packet, Product, Noun Phrase, Verb, Color, Parse Node, Feature Weight Array etc.).
На
количество типов не накладывается ограничений, оно зависит от специфики
приложения. Система типов в UIMA может быть организована в иерархию (таксономию). Например “компания”
может быть подтипом “огранизации”, а “группа существительного” – подтипом “узла
синтаксического разбора” (ParseNode).
Предположим, что тип “Person” описан как подтип аннотации (subtype of annotation). Аннотатор, например, может создать аннотацию “Person”, обнаружив упоминание о person между позициями 141 и 143 в документе D102. Аннотатор может создать и другую аннотацию person, обнаружив соответствующее упоминание между позициями 101 и 112. В структуре CAS может быть записана утверждение (statement), которое явно устанавливает, что оба фрагмента(span) ссылаются на одну и ту же сущность.
Для представления такого рода информации в систему типов вводится тип “сущность”. Этот тип – не аннатация. Ссылки на объект могут быть как в пределах одного документа, так в пределах коллекции документов (кросс-ссылки). Тип сущность имет свойство “вхождения” (occurrences), указывающее на все аннотации, рассматриваемые как упоминания о некоторой сущности.
Фрагменты, аннотированные как P1 и P2 могут иметь вид "Fred Center" и "He" соответственно. UIMA включает возможности для разрешения такого рода анафорических сылок путем указания, что эти аннотации ссыдаются на один и тот же объект.
UIMA поддерживает анализ, позволяющий одновременно иметь на документ несколько взглядов (multiple views), обеспечивая многомодальность обработки. Для того, чтобы сослаться на определенный “взгляд”, используется “субъект анализа” (subject of analysis - Sofa). Следовательно CAS может содержать один или несколько SOF, а результаты анализа представляют описание объекта для каждого.
Аннотатор – это один из компонентов UIMA. В архитектуру системы входит много других компонент, но все они требуют двух частей для своей реализации:
1. Декларативная часть и
2. Кодовая часть
Декларативная часть содержит метаданные, описывающие компонент, его идентичность(identity), структуру, поведение и называется “дескриптор компонента” (Component Descriptor). Дескрипторы компонента представлены в XML. Кодовая часть реализует алгоритм, она может быть программой на Java.
3.8.2. Пример простого приложения в UIMA
В качестве простого примера приложения UIM рассматривается Искатель Встреч (Meeting Finder). Это приложение анализирует e-mail пользователя на предмет поиска встреч, их времени, места, участников и пытается выявить основное содержание встречи. Искатель Встреч выполняет следующие задачи:
1. Доступ к документам: чтение e-mail сообщений электронной почты
2. Анализ документов: анализ каждого e-mail сообщения для обнаружения ссылок на встречи, идентификации их времени, места и субъектов.
3. Консолидация (Build collection) результатов анализа:
- построение индексов e-mail на основе ключевых слов и на содержании встречи;
- создание структурированной базы данных, включающей все упоминания встреч и ссылки, явно ассоциирующие содержание встречи с субъектами и авторами e-mail сообщений.
4. Интерпретация результатов (Deliver results): обеспечивает пользователя интерфейсом, позволяющем искать множества e-mail сообщений на основе комбинации ключевых слов и элементов встречи. Например, возможен запрос о нахождении всех встреч, относящихся к UIMA, проходящих в здании HAWTHORNE1 во время завтрака.
При решении этих задач предполагается:
- сообщения e-mail экспортируются и переводятся в нотацию Lotus;
- Искателю Встреч доступен ряд ранее реализованных компонент, в частности обеспечивающих сегментацию сообщений на предложения и обнаружение даты/времени;
- используются возможности XML для индексации элементов запроса и аннотаций.
- сформированные в результате анализа CAS-структуры допускают индексацию средствами XML.
При этих предположениях реализуются UIMA-компоненты, обеспечивающие решения всех вышеописанных задач доступа к документам, их анализа и консолидации результатов. Для получения нужной пользователю информации используется процессор XML-запросов (XML query processor). Детальная информация по UIMA описывается в документации [16],[17] .
3.8.3. Перспективы развития UIMA
Пример, поверхностно рассмотренный в 4.2., образует замкнутую систему, так как включает интерфейс, ориентированный на пользователя в виде XML-компонента. Однако, если CAS-структуры обеспечивают достаточную общность, этот интерфейс является относительно специфичным. Поэтому один из перспективных путей развития UIMA является совершенствование интерфейса с CAS-структурами в направлении большей общности.
Одна из интересных разработок IBM в этом направлении – сервисы SUKI для UIMA
(Component Services for Knowledge Integration in UIMA)
[19]. SUKI – это набор
сервисных компонент, предназначенных для трансформации результатов анализа
текста с помощью UIMA в
представление знаний (например, OWL) для формального вывода и обработки в базах
знаний и с помощью инструментальных средств WEB аналогичных Protege [20] и
Система Protégé также разработана в IBM и выполняет автоматическое назначение семантических тегов для более чем 264 миллиона web-страниц. Система обеспечила генерацию более 434 миллионов семантических тегов. Утверждается, что поиск релевантных запросу web-страниц значительно более эффективен. Система использует специальные алгоритмы, ориентированные на поддержку онтологии неоднозначных много-шкалированных данных (ontological disambiguation of large-scale data).
- RDF API
- чтение и запись RDF в RDF/XML, N3 и N-триплетах (N-Triples)
- OWL API
- In-память и persistent память
- RDQL – язык запросов для RDF
Сервисы SUKI ориентированы
на генерацию из сформированных UIMA CAS-структур
формального представления, которое может интерпретироваться базой знаний OWL. Обзор проблем,
возникающих при генерации такого рода формализмов при анализе текстов дан в
[22].
SUKI включает 4 главных компонента:
1) Знания уровня системы типов (Knowledge Level Type System - KLT)
2) Индексатор знаний (Knowledge Indexer)
3) База данных извлеченных знаний (Extracted
Knowledge Database - EKDB)
4) Интеграция знаний и механизмы трансформации (Knowledge Integration and Transformation Engine- KITE)
Первый компонент – минимальный уровень, ориентированный на систему типов UIMA и предназначенный для категоризации результатов анализа и их отображение в формальное представление знаний, точнее элементы формализма для OWL KB.
Второй – использует результаты первичного анализа и кореференции, индексируя эту информацию в реляционной базе.
Третий – это реляционная база данных и набор JDBC сервисов для запоминания и доступа к фрагментам знаний, сформированных на основе Индексатора знаний.
Четвертый – расширение KLT, отображает результаты UIMA в OWL-онтологию, а также позволяет получить RDF для OWL KB.
Более подробно эти фрагменты и их взаимодействие с UIMA рассмотрены в [23] .
3.9 Комментарии к обзору
3.9.1. Основные решаемые задачи
Перечисленные выше разработки показывают, что основными задачами, которые решаются при обработке больших объемов текстовой информации из глобальной сети, являются следующие:
- получение структурированной семантически значимой информации для последующей обработки в сферах политики и экономике;
в политике:
- общие тенденции развития политической ситуации;
- выявление реальных намерений политиков;
- выявление конфликтных и потенциально-опасных ситуаций.
в экономике:
- конкурентный анализ;
- информационная разведка;
- управление репутацией;
- изучение отраслевого рынка;
- оперативный мониторинг;
- выявление критических новостей.
- структуризация текстовой информации в базах данных для последующего
использования в системах извлечения знаний (Data Mining) и оперативного анализа (OLAP - технологии)
- автоматическое аннотирование документов в Интернет
- автоматическоя классификация документов в Интернет
- возможности естественно-языкового доступа к информации в Интернет (в частности к базам данных)
- высококачественный поиск в Интернет (по содержанию).
Задачи описаны достаточно крупно, например автоматическое аннотирование документов разбивается на аннотирование в научных целях (больший акцент на содержании) и аннотирование для поисковых целей в Интернет (больший акцент на гиперссылки, HTML и XML – детали и т.п.).
Вопросы информационной системы бизнес-разведки обсуждаются в [18], отмечаются, что использование соответствующих решений позволяет:
- постоянно отслеживать и анализировать
сведения о бизнесе конкурентов;
- организовать
мониторинг потоков с информацией о действиях конкурента (ценовая политика,
слияния и поглощения, рекламные объявления и анонсы, отзывы об их изделиях
и т.п.);
- раскрывать планы конкурентов;
- изучать
потенциальный спрос на продукцию и услуги;
- изучать
реакцию рынка на отдельные свойства товаров и услуг (например, с помощью
анализа тональности публикаций в прессе).
Среди
содержательных примеров описываются: ведение уголовных дел, проведение выборов, мониторинг мнения потребителей, оценка лояльности клиентов.
Отмечаются трудности при решении задач данного типа (характерные тем не менее и
для более общих задач, перечисленных выше). Одна из основных трудностей связана
с последовательным соблюдением трех основных принципов, диктуемых концепцией
бизнес-разведки:
- использование
единого информационного пространства взаимосвязанных фактов или гипотез
вне зависимости от типа содержимого источников информации;
- связь фактов
или гипотез с релевантными источниками информации, то есть аргументированность
фактов и гипотез;
- применение
исторически-пространственной информационной модели баз данных фактов и
гипотез.
Итак для каждого факта или гипотезы требуется наличие атрибута места и времени, а также невозможность их безвозвратного удаления. Другая трудность связана с проблемами преобразования различных форм представления знаний. Утверждается, что “…основная причина относительно малого объема рынка систем извлечения знаний и систем поддержки принятия решений состоит в том, что практически ни одна система аналитической обработки не выполняет формально-семантической интерпретации результатов своей работы (хотя бы за счет их семантического ранжирования). ”
В силу этого существует понятийный разрыв между результатами работы систем типа Knowledge Discovery и Data Mining и входом систем поддержки принятия решений. Разрыв это преодолевается за счет использования дополнительных программ, результаты работы которых интерпретирует эксперт-аналитик. Однако при этом обычно добытые знания теряют наглядность («упрятываются» в документы) и теряется их аргументация.
Концептуальная и базовая информационные модели системы бизнес-разведки, иллюстрируются на примере программы Xfiles, разработанной с использованием программных компонентов компаний Oracle, «Гарант-Парк-Интернет», Inxight, ABBYY Software House и Altova [18].
В статье “ ИНТЕРНЕТ СЛЕДУЮЩЕГО ПОКОЛЕНИЯ ” [13] отмечен ряд интересных задач несколько более общего характера, чем перечисленные выше:
-
слежение за
изменениями в области
интереса личности или органа управления, а также поиск и изучение всего прошлого опыта;
-
нахождение в
текстах определений любых терминов с целью уточнения их смысла и
выявления связанных понятий;
- поиска аналогий с проблемной ситуацией или суждением (правилом), а также непосредственного поиска фрагментов текста, вероятно вступающего в противоречие с заданным суждением (правилом);
-
автоматическая классификация
неограниченных распределенных массивов текстов;
- обеспечение открытых технологий
образования в ИНТЕРНЕТ;
-
обеспечение распределенных
многоязычных средах в ИНТЕРНЕТ.
Можно отметить какая интересная задача практически не решается перечисленными разработками – это задача анализа текстов программ. Было бы интересно автоматически получить какие либо знания о программных кодах (не выявляемые системами компиляции) например :
- семантическую сеть системы программ с комментариями;
- сведения о нарушении страндартов программирования;
- рекомендации по улучшении программного кода;
- комментарии по стилю программирования;
- указания на потенциальные ошибки (с учетом предметной области);
- аннотации на естественном языке к подпрограммам.
3.9.2. Общие выводы
На основании рассмотренных выше разработок можно сделать вывод, что спектр систем для анализа больших объемов текстовой информации достаточно широк, но параллельную алгоритмику используют вероятно лишь единицы. Трудно также выделить очевидного доминирующего лидера на Российском рынке. Принципиально практически все системы используют схему шаблонов, выделяющих в тексте фрагменты, отображаемые далее в формализованное представление (обычно в таблицы базы данных).
Очевидно в маркетинговых целях разработчики ряда систем утверждают, что сколько-нибудь близкие программы такого класса как их система не появятся на рынке еще как минимум несколько лет. При этом отмечается, что разработки в данном направлении были начаты несколько лет назад (3-5).
Предполагаем, что реального прорыва (на пути эволюционного
развития) в области обработки неструктурированных данных следует ожидать при
комбинированном подходе, включающем:
-
параллельные
алгоритмы и ориентацию на многоагентную обработку;
-
развитую
систему представления знаний;
-
высокий уровень
инструментальных средств;
-
разумный учет
лингвистических атрибутов;
-
возможности
обучения и самообучения системы путем сканирования произвольных текстов (“раскрутка”
базы знаний системы).
Очевиден естественный параллелизм при обработке больших объемов текстовой информации многих из перечисленных задач. Подлежащие документы разбиваются на группы, каждая из которых обрабатывается достаточно независимо (задачи аннотирования, классификации, поиска). Естественно также возникает параллелизм при исследовании когнитивных моделей, использующих принципы имтитационного моделирования (GPSS, и более современные методы многоагентной обработки).
Целесообразно и относительно несложно использование параллелизма и при начальном формировании базы знаний (например, при автоматическом нахождении морфологических и синтаксических свойств словоформ). Вопросы параллельной обработки зависимых друг от друга компонент, очевидено, требуют значительно большей проработки синхронизации, чем простые диспетчеры для относительно независимых компонет.
Описанный
в разделе 3.5. язык онтологий в Web (OWL) базируется на логическом
выводе в стиле известного языка Пролог. В силу этого одним из интересных направлений
в параллельной обработке может стать использование кластеров для логического
вывода. Напомним, что еще в 80-ые годы широко обсуждались алгоритмы параллельного
логического вывода (в частности, с использованием метода резолюций) и реализации
Пролог-машины.
Развитая система представления знаний предполагает удобный интерфейс пользователя для ввода и редактирования знаний более высокого уровня, чем типичные интерфейсы к базам данных или текстовые конфигурационные файлы. Базовый понятийный уровень системы представления знаний должен быть достаточно высок и соблюдать целесообразный баланс между декларативной компонентой (описательная часть, иерархии понятий и т.д.) и процедуральной компонентой (верификация знаний, возможности вывода/умозаключений и т.п.). На наш взгляд, именно представление знаний является основным системообразующим элементом.
Высокий уровень инструментальных средств означает использование языков как минимум уровня 4GL и SQL, а также специальных языков, ориентированных на текстовую обработку. Разумный учет лингвистических атрибутов означает отказ от тонких и трудно формализуемых лингвистических деталей. Целесообразнее сделать акцент на статистических методах и на эвристиках, теоретически не гарантирующих результат, но практически весьма эффективных.
Обучение и самообучение системы понимается в достаточно узком смысле. В частности система должна автоматически строить предположения о морфологических, синтаксических и семантических характеристиках незнакомых слов, исходя из контекста и соответствующих эвристик. Система должна объяснять пользователю свои предположения, предъявляя контексты и использованные эвристики. Такие возможности позволят резко упростить сопровождение системы.
В расширенном понимании самообучение системы предполагает упомянутую “раскрутку” базы знаний с помощью разработки некоторого фундаментального концептуального ядра и сервисов, позволяющих путем сканирования произвольных ЕЯ-текстов строить предположения (гипотезы) и искать для них подтверждения (опровержения). Стиль такой раскрутки намечен в фундаментальных исследованиях, описанных в разделе 4. Вопрос об использовании результатов этих исследований требует специальной проработки.
4. Проекты, поддержанные РФФИ
Далее в разделах 4.1. и 4.2. дается общая характеристика проектов, поддержанных Российским Фондом Фундаментальных Исследований (РФФИ). Проекты выполнялись по тематике “Средства создания и поддержки систем баз знаний и экспертных систем” (код классификатора 07-161). Срок выполнения каждого проекта – три года, первый проект завершен в 2004 году, второй – начат в 2005.
4.1. Проект 2002-2004 гг.
4.1.1. Основная концепция
Наименование проекта - “Инструментальные программные средства для общения на естественном языке с базами данных и экспертными системами”. Проект выполнялся в 2002-2004 гг. (№ проекта 02-07-90180 в) и был ориентирован на автоматизированное построение ЕЯ-интерфейса, используя схему реляционной базы и ее содержимое в качестве исходной информации. При этом сопровождение лингвистического обеспечения системы общения выполняется путем анализа ЕЯ-текстов произвольных объемов и содержания, а также на анализ схемы и данных произвольных реляционных баз с целью выявления соответствия объектов базы данных (таблиц, атрибутов, значений атрибутов) объектам ЕЯ-природы. Разумеется язык общения является существенно ограниченным естественно-подобным языком (ОЕЯ).
Концепция данного подхода сформулирована в [24] и на общем уровне описывается следующим образом:
- ОЕЯ-система ориентирована на общение с произвольными реляционными базами с помощью автоматически генерируемой SQL-программы;
- используя схему этой базы, хранимые в ней данные и собственную базу знаний, система выдвигает предположения о содержательном описании хранимых данных и способах его отображения в структурах базы данных;
- система пытается подтвердить (или опровергнуть) выдвинутые предположения;
- на основе подтвержденных предположений система осуществляет генерацию интерфейса, позволяющего общаться с базой данных на ограниченном естественном языке;
- пополнение словаря системы происходит путем анализа ОЕЯ-текстов произвольных объемов.
На начальном этапе (до анализа схемы и содержимого базы данных) должна быть подготовлена эталонная база, которая содержит сведения об объектах, которые могут храниться в реляционной базе (далее называемой рабочей). Кроме того эталонная база содержит общие знания о схемах баз данных (таблицы, атрибуты, первичные/внешние ключи, типы данных и т.д.). Первичные кандидаты на включение в такую базу: единицы измерения, валюты, сведения о времени, географические сведения и т.п.
Эталонная база подготавливается с относительно низким уровнем автоматизации (обычные меню). Однако последующее пополнение этой базы должно выполняться автоматически путем сканирования ЕЯ-текстов произвольного объема и содержания. С практической точки зрения модель мира в данном проекте может быть ограничена следующим образом: имеет смысл только то, что может быть представлено как корректный SQL-код для рабочей базы. Центральным моментом здесь является то, что реляционная база служит естественным формализмом того подмножства ОЕЯ, которое описывает хранимые в базе сущности.
Для автоматического извлечения общих знаний о морфологии и синтаксисе были реализованы эвристики, которые строили предположения о характеристике незнакомых слов. Далее предположения анализировались путем поиска вхождений этих слов в произвольные тексты и рассмотрения соответствующих контекстов. В случае соответствия контекстов эвристическому правилу вес предположения увеличивался. При достижении достаточно большого веса предположение считалось достоверным.
Разработанный в проекте синтаксический анализатор применяет упрощенные методы при работе с моделью управления слов и ориентирован на полноту синтаксических связей в большей степени, чем на получение однозначной синтаксической структуры.
Для пояснения сути развиваемого подхода кратко перечислим этапы создания интерфейса и приведем упрощенный пример, наглядно демонстрирующий схему работы системы.
Этапы создания ЕЯ-интерфейса
1) подготовка эталонной базы
2) пополнение эталонной базы путем сканирования ЕЯ-текстов
3) анализ рабочей базы
4) сопоставление объектов базы данных и ЕЯ- объектов
5) генерация ЕЯ-интерфейса
6) тестирование интерфейса и его отладка (итеративно!)
ПРИМЕР.
Допустим в результате анализа большого корпуса текстов в эталонной базе сформировано семантическое описание, включающее свойства и отношения понятия “сотрудник” (синоним – “служащий”, более общее понятие “человек”):
<сотрудник имеет_атрибуты фамилия,имя,отчество>
<сотрудник имеет_атрибут дата_рождения>
<сотрудник имеет_атрибут зарплата>
<сотрудник имеет_атрибут пол>
<сотрудник находится_в_отношении_работать организация>
и т.д. Детали формирования элементов такого описания приводится в [25].
Семантичность этого описания в том, что в процессе сканирования текстов для атрибутов формируется множество типичных значений и статистически найденные соотношения между ними (например, что “дата рождения” всегда меньше “дата поступления на работу” или “дата вступления в брак”).
Пусть далее имеется рабочая база данных с таблицей типа “Person” (или “Employ”) и атрибутами типа “name”, “data_br”, “salary”, “sex” и т.п. На основании ряда эвристических правил (в частности - значения атрибута “name” и наименование таблицы) система выдвигает предположение, что “Person” соответствует ЕЯ-объекту “сотрудник” (или “служащий”). Далее для прочих атрибутов таблицы “Person” также используютс эвристические правила для значений атрибутов и их наименований, что позволяет выдвинуть предположения о соответствии этим атрибутам объектов ЕЯ-природы.
Даже в случае частичного успеха таких предположений система обеспечивает примитивный ЕЯ-интерфейс, позволяющий отвечать на запросы типа:
Перечислить фио всех сотрудников
Какова дата рождения сотрудника Иванова Ивана Ивановича?
Найти сотрудников с зарплатой более 500
и т.д. (в зависимости от успешного подтверждения предположений)
Разумеется, реальная ситуация существенно сложнее этого схематичного примера. Рассмотрим более подробно предположения, выдвигаемые при анализе схемы базы. На первом шаге определяются размерности таблиц БД и выделяется ряд описаний символьного характера для передачи их на вход лингвистического транслятора (ЛИНГТ). Эти описания могут относиться как к схеме БД, так и к содержимому (атрибуты, имеющие тип “character”). Перечислим шаги анализа, ассоциируемые с выдвигаемыми предположениями:
1. Справочники БД.
2. Сущности, соответствующие справочникам.
3. Первичные/внешние ключи.
4. Иерахия сущностей в БД.
5. Соответствие сущностей БД сущностям ОЕЯ.
6. Связи между сущностями БД.
7. Предметная область БД.
8. События (таблицы, имеющие поля типа “date”).
9. Связанные нормализованные таблицы.
Перечисленные шаги не являются независимыми, а для ряда из них имеются очевидные эвристики, например:
- для 1 – таблицы с двумя полями (числовое и символьное), причем числовое – первичный ключ целесообразно проверять на справочники (символьные поля анализировать с помощью ЛИНГТ);
- предположения шага 3 целесообразно проверять непосредственно, выполняя
SELECT-запросы (если на первичный ключ нет указаний в БД);
- предположения шага 7 выдвигаются на основе экспресс-анализа символьных
значения в БД и описаний таблиц в схеме БД (мнемоника, метки – LABEL,
дескрипторы и т.д.);
- иерархию сущностей в БД естественно искать, используя иерархию в ОЕЯ.
- шаги 5, 6 и 9 связаны (целесообразно искать 6, используя 5; а 9, используя 6 и информацию о размерностях таблиц).
В работах [26] и [27] более подробно описывается общая логика механизмов анализа схемы и данных произвольной реляционной базы, позволяющих рассматривать схему и содержимое реляционной базы как исходные данные для выдвижения предположений об объектах базы данных и их соответствии объектам естественного языка. Здесь только заметим, что нормализованные таблицы могут не иметь естественного для предметной области ОЕЯ-описания. Это связано с тем, что они отражают эффективное с точки зрения обработки представление данных.
Например, “поставка товара” как цельный первичный документ содержит обычно общие характеристики поставки (“дата”, “поставщик”, “сумма” и т.п.), а также перечень собственно объектов поставки. В нормализованных таблицах такой документ обычно представляется как “заголовок документа” и “спецификация документа”. Эвристики в этом случае более сложны, они должны учитывать размерности таблиц, первичный ключ заголовка, его вхождение в качестве внешнего ключа в спецификацию и т.д.
Отметим также, что ОЕЯ-описание сущностей, связанных с процедурами обработки данных в базе, не рассматривалось в рамках данного подхода. Например, сущность “количество товара на дату” может относительно сложно вычисляться путем выборки данных из таблиц “приход товара”, “продажа товара” и т.п. Вопрос о ОЕЯ-описании такого рода процедур и автоматической генерации соответствующего программного кода требует специального исследования.
4.1.2. Априорная модель данных
Априорная модель реализуется в эталонной базе и разрабатывается как стандартная реляционная СУБД. Отметим, что обычное концептуальное описание данных организуется как надстройка над конкретной СУБД и поэтому обладает ограниченной общностью. В отличие от этого априорная модель ориентирована на максимальную общность описания. В схеме априорной модели можно выделить таблицы, определяющие схему модели мира (заполняются разработчиком) и таблицы, реализующие собственно модель мира (в основном должны заполняться путем сканирования ЕЯ-текстов).
Измеряемые
величины
Ориентация на прикладные задачи (автоматизированное построение ЕЯ-интерфейса для баз данных и экспертных систем) диктует выбор объектов-концептов, но не определяет общность их представления. В текущей реализации эталонной базы в эскизном варианте разработаны таблицы для представления материальных объектов, их свойств и отношений и более детально разработаны таблицы для представления единиц измерения. Это представление базируется на понятии “измеряемая величина”, а при представлении последней используются наиболее общие понятия: <время>, <расстояние>, <масса>, <сила>, <температура> и т.д.
Опуская ряд технических деталей приведем упрощенный фрагмент таблицы “ априорные измеряемые величины” :
|
№ |
ЯПЗ-описание |
ЕЯ-описание |
Базовая единица |
Эвристики “измер” |
Аксиома-тика |
|
1 |
<время> |
время |
секунда |
|
|
|
2 |
<расстояние> |
длина |
метр |
|
|
|
3 |
< масса > |
масса |
грамм |
|
|
|
4 |
< сила > |
сила |
ньютон |
|
|
|
5 |
<температура > |
температура |
градус |
|
|
Фгагмент таблицы “эмпирические
измеряемые величины”:
|
№ |
Ссылка на Измер.вел. |
ЯПЗ-описание ссылки |
ЕЯ-описание |
Соотношение с базовой ед. |
Размытое описание |
|
25 |
1 |
№ измеряемой величины = 1 <время> |
Час |
3600 |
Нет |
|
55 |
1 |
№ измеряемой величины = 1 <время> |
утро |
Несколько часов |
Часть суток |
Элементы таблицы “измеряемые величины” (априорные) заносятся разработчиком, элементы таблицы “эмпирические измеряемые величины” формируются автоматически путем сканирования ЕЯ-текстов. При формировании используются эвристики, как общие для любых измеряемых величин, так и специфичные для данной (априорной) величины.
Примеры эвристик:
1) Если есть ЕЯ-контекст “<X> <измеряться в> <Y>”,
То <X> - <измеряемая величина> , а <Y> - <единица измерения>
2) Если есть ЕЯ-контекст “<X> <больше, меньше …> <Y>”
и “<X> <единица измерения>,
То <Y> - <единица измерения>
3) “<Y> <единица измерения> <X> - аналогично 1.
Нахождение ЕЯ-контекстов выполняется в 2 этапа – на первом находятся вхождения ключевой основы (например “измер”), на втором используется упрощенный морфо-синтаксический анализ для сопоставления синтаксической структуры правила со структурой предложения, содержащего вхождения ключевой основы. Результаты успешного применения эвристики фиксируются в таблице “эмпирические измеряемые величины”, а информация об умозаключении (основания, данные за/против, комментарии) в общей таблице гипотез.
Подчеркнем, что такое представление ориентировано, во-первых, на фундаментальные свойства измеряемых величин, а во-вторых, на механизмы автоматической детализации априорных измеряемых величин путем нахождения фрагментов ЕЯ-фраз, позволяющих выдвинуть эмпирические предположения (пусть неполные, а возможно и ошибочные). Именно эти особенности являются центральным моментом развиваемого подхода. Пример пусть и весьма общего, но стандартного подхода: ввод всех единиц измерения системы СИ, дополненного наиболее распространенными нестандартными единицами и наличие формального интерфейса, позволяющего вводить новые единицы.
В отличие от такого стандартного подхода целью вышеописанного представления является не только фундаментальность и автоматическая детализация, но и общность механизмов выдвижения и верификации предположений на основе произвольных ЕЯ-текстов. Работа с эвристиками в виде ЕЯ-подобных структур для “измеряемых величин“ в значительной степени аналогична работе с такими же эвристиками для предположений о морфологических и синтаксических характеристиках словоформ. При этом структура таблицы гипотез ориентирована на максимальную независимость от содержательной интерпретации предположений (гипотез).
Поле “Ссылка на Измер.вел.” фрагмента таблицы “эмпирические измеряемые величины” является стандартным внешним ключом, ссылающимся на первичный ключ таблицы “ априорные измеряемые величины”. Однако помимо этой стандартной ссылки, которая должна быть интерпретирована программными средствами СУБД, в следующем поле содержится семантическое описание, предназначенное для интерпретации механизмами языка представления знаний. Такое представление ориентировано на тесное взаимодействие программных средств баз данных и языков представления знаний, обеспечение “семантичности” базы данных на уровне нестандартного поиска.
В поле “аксиоматика” содержится ссылка на множества правил, задающих наиболее общие свойства измеряемой величины. Эти правила непосредственно не используются при автоматическом формировании “эмпирических измеряемых величин”, предполагается, что они будут использованы в дальнейшем при семантическом анализе ЕЯ-текстов. Поскольку таблица приведена в упрощенном виде, некоторые поля (в частности определяющие физические/абстрактные свойства величины) опущены. Отметим, что допускается большая степень неопределенности при выдвижении предположений, в частности не требуется обязательного отнесения эмпирической измеряемой величины к априорной и обязательного соотношения с базовой единицей
Иерархии
Фундаментальное описание иерархий в качестве основы рассматривает иерахию “часть-целое”, естественно выделяемую в физическом мире. Аксиоматика этой иерархии должна прежде всего описывать такое свойство как “часть не больше целого”, причем в физическом смысле это означает “размеры части не больше размеров целого” и “масса части не больше массы целого”. Более тонкие свойства могут описывать вхождение веществ в целое и части (или невхождение), перемещение целого и части и т.п. При всей тривиальности этих утверждений (с точки зрения человека), они играют большую роль при выдвижении и проверки предположений об объектах, хранимых в базах данных. Значения полей таблиц задают статистику, позволяющую получить значительно больше информации о хранимых в базе объектах, чем это может показаться на первый взгляд.
Описание объектов, свойств и иерархий в качестве обязательной компоненты содержит ссылку на представление объекта в РБД, т.е. описание иерархии в модели и ее представление в базе. Для больших иерархий целесообразно иметь схемное описание с примерами на нижнем уровне и ссылкой на источник элементов нижнего уровня (таблица БД, тексты информационного характера – словари, справочники, учебники и т.п.).
Средства описания иерархий в эталонной базе включает как системное описание иерархий, так и описание представления иерархий в рабочей СУБД (соответствие, если оно есть, также может быть описано). Системные иерархии формируются автоматически путем выдвижения гипотез и их проверки на произвольных ЕЯ-текстах (в основном на энциклопедии).
Системное описание включает две таблицы: первая задает наименование иерархии, ее уникальный номер и ссылку на таблицу гипотез (сформировавших данную иерархию), вторая определяет собственно иерархию (ссылка на первую таблицу, ссылку “вверх” на “предка”, и т.д.). Описание представления в СУБД включает операторы SELECT для выбора уникального “листа”, для выбора класса по заданному “листу”, для выбора надкласса по заданному классу и возможно SELECT операторы для выбора ЕЯ-наименований “листьев” и классов. Описание системных таблиц также могут быть включены в такое представление.
Наличие вышеприведенных описаний позволяет в первом приближении ввести понятие “материальный объект” с характеристиками типа “физическая локализация”, “временная локализация”, “вхождение в иерархию часть-целое …”, “физические свойства”. Для выделения материального объекта и его характеристик путем сканирования текстов предполагается использовать те же механизмы выдвижения и верификации гипотез, что и для работы с измеряемыми величинами (и для выявления морфо-синтаксических характеристик). В настоящее время ведутся программные эксперименты, позволяющие автоматически выявлять характеристики материального объекта.
Вопрос об автоматическом формировании глобальной иерархии “большое-малое” для материальных объектов типа “метагалактика - галактика – солнечная система – планета Земля – материк – страна – город – улица – дом – квартира – человек – мышь – муравей – инфузория – клетка – ДНК – молекула – атом – электрон - кварк ” с автоматическим же определением диапазона расстояний или такой спектр следует занести заранее также является предметом экспериментов.
4.1.3. Тестирование
В экспериментальном варианте возможности инструментальных средств для автоматизированного построения ЕЯ-интерфейса были протестированы на реальной базе данных. База данных содержит постоянно обновляемую информацию о предприятии розничной торговли и содержит более 200 таблиц. Система программных инструментальных средств позволяет использовать базу данных и ее содержимое для автоматизированной генерации модели, обеспечивающей доступ к базе на ограниченном естественном языке (ОРЯ). Подчеркнем, что модель может фиксировать результаты с достаточно большой степенью неопределенности и даже ошибочности, однако должна позволять как снимать неопределенность, так и отказываться от ошибочных предположений при поступлении соответствующей информации.
Главный экран системы включает элементы управления для вызова инструментальных средств и тестирования результатов их выполнения. Поскольку инструментальные средства должны позволять генерацию ЕЯ-интерфейса для произвольной предметной области, экран не содержит элементов управления, ориентированных на конкретную СУБД с данными. Элементы оперируют с общими понятиями (типа объект, свойство, отношение, значение и т.п.) и с предикатами общелогического типа (равно, больше, меньше, принадлежит, начинается с, входит в и т.п.).
Большинство пунктов управления ориентировано на рабочий режим – формирование ЕЯ-запроса к базе данных в диалоге с пользователем, его выполнение и выдача результатов. Один из главных пунктов (адаптация) обеспечивает вызов программных средств, автоматизирующих извлечение общеязыковых знаний, средств для анализа схемы и содержимого рабочей базы, сервисных средств для организации диалога пользователя и администратора базы с системой.
Тестирование прошли:
- инструментальные средства для извлечения общеязыковых знаний ;
- инструментальные средства для анализа схемы базы данных;
- инструментальные средства, ориентированные на анализ содержимого базы данных;
- cервисные средства (адаптация, диалог, и т.д.)
Разумеется, технология построения ЕЯ-интерфейса реализована в макетном варианте и для создания промышленной версии требуется весьма существенная доработка. Однако полученные экспериментальные результаты представляются интересными как в теоретическом, так и в практическом аспектах.
ЕЯ-запрос к базе данных может быть введен непосредственно, однако для помощи пользователю (обладающему весьма скромными навыками работы с компьютером, например, работающем с WORD) реализован сервис, включающий подсказки
- желаемых действий (с помощью вопросительных слов или императивов типа “найти”, “перечислить” и т.п.);
- ЕЯ-наименований объектов, их свойств и отношений (по результатам анализа схемы базы данных;
- значений свойств (из базы данных);
- типовых запросов, которые пользователь может вызвать и отредактировать в нужном ему варианте;
- для сохранения запросов, которые система не смогла обработать (с целью последующего анализа причин неудачи и возможной корректировки базы знаний системы как в автоматическом режиме, так и администратором базы).
Типовые запросы могут либо автоматически генерироваться системой, либо вводиться администратором базы данных (вместе с их SQL-описаниями). В последнем случае эти запросы используются для обобщения как это описано в [28]. Были подготовлены тестовые примеры для проверки возможностей:
- выяснения некорректности запроса с общеязыковой точки зрения (с выдачей фрагментов ЕЯ-текстов, на основании которых сделан вывод о некорректности);
- объяснения пользователю, что для корректного запроса (с общеязыковой точки зрения) в базе данных нет сущностей, моделирующих запрашиваемые объекты или их свойства (нет SQL-описания запроса);
- содержательного объяснения пользователю причин, по которым в базе отсутствует информация для корректного запроса, успешно транслированного в SQL;
- диалога с пользователем для уточнения или переформулировки запроса;
- успешной трансляции запроса в SQL, его выполнения и выдачи результатов.
В экспериментальном варианте тестирование в целом прошло успешно. Анализ результатов в целом показал перспективность развиваемого подхода и его несомненный прикладной потенциал. В данный момент связь фундаментальных свойств, описываемых в эталонной базе, с объектами рабочей базы весьма слаба. Тем не менее предполагается, что именно усиление этой связи должно стать основным прикладным аспектом и точкой роста при практическом использовании подхода.
4.2. Проект 2005-2007 гг
Наименование
проекта - “Инструментальные программные средства для представления фундаментальных и конкретных знаний в
системах общения с ЭВМ на естественном языке”. Проект рассчитан на выполнение в
2005-2007 гг. (№ проекта 05-07-90200 в) и ориентирован разработку
инструментальных программных средств для автоматизации процесса формирования
конкретных знаний по произвольным предметным областям путем сканирования
соответствующих текстов на естественном языке. Разрабатываемые программные
средства должны обеспечить формирование базы знаний для любых областей и
автоматизированную генерацию естественно-языкового интерфейса для общения с
формируемой базой знаний.
Данный проект существенно опирается на результаты проекта, описанного в разделе 5.1. и на первом этапе использует тексты энциклопедического характера (БСЭ). Ведутся эксперименты по автоматическому построению из этих текстов иерахий и извлечению данных о физических объектах с их характеристиками. При этом морфологические и синтаксические свойства словоформ из текстов БСЭ в подавляющем большинстве определяются с помощью средств, разработанных в предшествующем проекте. Поскольку это проект находится в стадии начального выполнения, детали его концепции здесь не рассматриваются.
4.3. Рекомендации по использовании
результатов проектов
Разумеется, полученные в процессе фундаментальных исследований результаты носят экспериментальный характер, однако они могут быть полезны не только для определения точек роста и направления дальнейших НИР и ОКР, но и для прикладных разработок. Механизмы автоматического формирования базы знаний могут резко снизить трудоемкость как создания базы, так и ее сопровождения. Концепция эталонной базы с понятиями очень высокого уровня может послужить целям разработки соответствующих стандартов представления знаний.
Большая общность фундаментального подхода позволила бы устранить определенную незавершенность, например системы ConExT. Результат работы этой системы – база данных, сформированная путем обработки ЕЯ-текстов. Использование результатов – отдельная задача. Но если рассматривать задачу в расширенной постановке, то ее можно трактовать как генерацию SQL-кода для базы данных с результатами. Этот код тривиален и сводится к выполнению операции INSERT.
При анализе ЕЯ-текстов ConExT использует некоторые механизмы, извлекающие содержательную часть и помещающие ее в реляционную базу. Целесообразно при запросе к этой базе использовать не только непосредственный формализм SQL (или специализированный интерфейс типа меню), но и ЕЯ-доступ. Рассматривая запрос пользователя на ЕЯ как некоторый текст и применяя те же механизмы извлечения содержания, что и при формировании базы, естественна попытка автоматически получить SQL-запрос, адекватный ЕЯ-запросу пользователя. Система при этом приобретает большую целостность, а соответствующие механизмы – большую универсальность.
Эталонная база содержит понятия очень высокого уровня и поэтому связанные с ними утверждения выглядят тривиально и малосодержательно (как и многие аксиомы вообще). Но именно это позволяет как увеличивать достоверность выводимых знаний, так и объяснить пользователю обоснования выводов в конечном счете на уровне фундаментальных законов внешнего мира. Действительно, если из некоторого утверждения можно строго вывести тривиальное сомнительное утверждение, то и это утверждение можно считать сомнительным (а это уже может быть новым знанием!).
Стиль использования эталонной базы можно проиллюстрировать рис. 4. Здесь на нижнем уровне находится схема базы и собственно данные, далее идет концептуальная схема, обобщенно представляющая содержание базы (на этом уровне уже возможен ЕЯ-интерфейс). Наконец, на верхнем уровне находится эталонная база с понятиями самого высокого уровня. Одна из основных функций этой базы – обеспечить наследование свойств и аксиоматики для элементов концептуальной схемы.
Предполагается, что при создании концептуальной схемы для другой базы, в которой, например дискретность времени задается не датами, а часами (минутами, секундами, микросекундами, а возможно и годами, десятилетиями и т.д.) общие механизмы работы с понятием “время” наследовались бы из эталонной базы с соответствующими модификациями. Аналогичное наследование предполагается обеспечить и для других объектов (не только “человек” и “организация”, но и “причина/следствие”, “физический объект/абстрактный объект ” и т.д.).
Аксиоматика верхнего уровня должна связывать общие категории очевидными для человека (но не для системы!) утверждениями типа “причина должна предшествовать следствию” или “физическая локализация части не превосходит физической локализации целого”. Такой подход позволит существенно упростить построение концептуальной схемы.
Обобщая этот подход, можно рассматривать на нижнем уровне не только базы данных, но тексты, а концептуальную схему рассматривать как результат структуризации этих текстов. При этом вышеупомянутые преимущества подхода с использованием эталонной базы естественно переносятся на обобщенную схему. Особенно привлекательно в этом случае сохранение возможности автоматизированного построения ЕЯ-интерфейса.
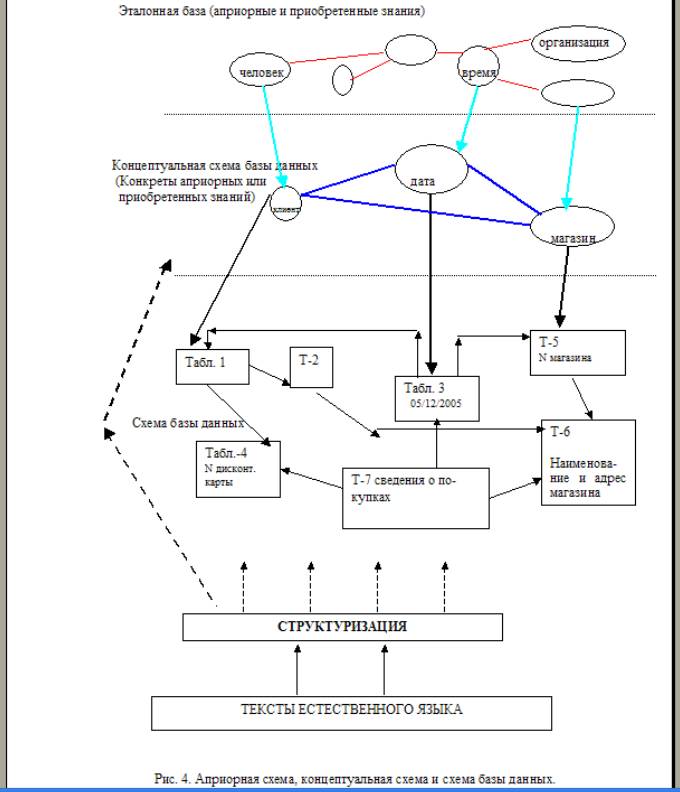
4.4.
Данные и знания.
Человек интуитивно ощущает разницу между данными и знаниями. Однако дать достаточно строгое определение этой разницы, принятое большинством специалистов по ИИ, не удается. Граница между данными и знаниями размыта, нечетка и напоминает границу между “есть борода” и “нет бороды”. Не вступая в дискуссию по поводу определения знаний, будем опираться на интуитивное понимание этого термина человеком. Однако выскажем некоторые общие соображения на тему “знание”, аналогичные тем, которые описывают (не определяют!) такое фундаментальное математическое понятие как “множество” (совокупность, некоторое собрание элементов, коллекция). Достаточно подробные и конкретные соображение на эту же тему приведены в статье “Информация и знания: невидимая грань” [29]. В этой же работе обсуждаются вопросы организации информации и доступа к ней (в частности, автоматизация построения гипертекстов, машинного аннотирования и т.п.)
Данные (информация) ассоциируются не столько с носителем данных (он может иметь различную физическую природу), сколько с механизмами интерпретации. В качестве интерпретатора может выступать как человек, так и ЭВМ. Интерпретация данных, которая сводится к стандартным вычислениям, обычно не воспринимается человеком как обработка знаний. Но в тех ситуациях, когда либо данные, либо некоторые представления человека обобщаются и после такого обобщения (что важно!) оказывается возможным предсказать новые явления на других данных (представлениях) это уже претендует на работу со знаниями.
Примеры:
1) Анализируя астрономические таблицы, Кеплер вывел известные эмпирические
законы движения планет.
2) До Ньютона человеку было очевидно, что для передвижения тела большей
массы требуется приложить большую силу, но только с открытием формулы a=F/m этим интуитивно очевидным представлениям человека было придано точное количественное выражение (получено новое знание).
Очевидно, что современные средства Dana Mining позволят легко вывести как законы Кеплера, так и первый закон Ньютона (на соответствующих массивах данных). Именно поэтому они и называются средствами извлечения знаний. Однако человек связывает со знаниями возможности их организации в сложные иерархические структуры (с преемственностью знаний) и гибкого использования различных знаний в сходных по типу ситуациях. Иллюстрацией первого являются закон всемирного тяготения, обобщающий законы Кеплера и далее современные физические представления, обобщающие механику Ньютона. Аналогично эмпирические знания о законах Ома и Ампера обобщаются системой уравнений Максвелла. Современным системам извлечения знаний построение таких иерархий пока недоступно.
Гибкое использование человеком знаний о морфологии, синтаксисе и семантике проиллюcтрируем следующими хрестоматийными примерами. Фраза “глокая куздра штеко будланула бокра и кудрючит бокренка” строго говоря лишена смысла (семантики), однако обычно человек как носитель языка, опираясь на знания морфологии и синтаксиса, на каком-то уровне понимает ее. Это условное “понимание” позволяет отвечать на вопросы типа: “Какая куздра?”, “Что она делает и в каком времени?” и т.п.
Другой пример – это набор слов “автомобиль”, “скользкий”, “дорога”, “ехать”. Обычно носитель языка легко строит соответствующую осмысленную фразу (автомобиль едет по скользкой дороге), опираясь, очевидно, на семантику данных слов. Эти примеры иллюстрируют, что недостаточно только знаний о морфологии, синтаксисе и семантике, нужны еще и знания о гибком использовании имеющихся знаний (метазнания). В современных системах представления знаний такого рода механизмы развиты явно недостаточно.
Спектр Данные => Информация => Знания можно проиллюстрировать на следующем упрощенном примере:
Пусть в базе хранятся числовые данные, определяющие вершины треугольников.
С помощью средств СУБД эти данные можно извлекать, сортировать, суммировать и т.д., но они остаются именно данными.
Если написаны программы, позволяющие вычислять площади треугольников или их углы по сторонам, то это уже информация.
Если же построена модель, в общем виде фиксирующая понятие треугольник (и средства его определения по известным признакам равентва треугольников) и позволяющая автоматически классифицировать треугольники (например, выделяя прямоугольные), то можно говорить о знаниях.
Аксиоматический уровень знаний, позволяющий опираться на аксиомы и пересматривать их, пока недоступен современным базам знаний.
Если при интерпретации данных используется модель внешнего мира и эта интерпретация используется для организации целеориентированного поведения, то можно говорить, что модель содержит знания. Например, древний охотник, интерпретируя данные о следах зверя, мог настигнуть добычу, зная повадки зверя. Но если результатом интерпретации данных является корректировка самой модели внешнего мира, то естественно говорить о приобретении знаний. Таким образом знания связываются с наличием модели внешнего мира и возможностями ее модификации. Современные системы представления знаний предлагают возможности описания моделей и некоторые механизмы обработки, однако пока они весьма далеки от возможностей человека.
Именно возможности корректировки позволяют говорить о полноценных знаниях, иначе к знаниям нужно отнести, например, генетическую информацию, закодированную в ДНК. Действительно, ее интерпретация позволяет построить целостный организм. Вероятно, можно говорить о генетических знаниях, однако важным свойством модифицируемости эта информация практически не обладает, она достаточно жесткая и неизменяемая.
Организация “модели” внешнего мира у человека интенсивно исследовалась нейрофизиолагами, психологами и специалистам по искусственному интеллекту. Однако воплотить результаты этих исследований в виде системы, полноценно использующей знания, пока не удается. Важно в частности, что “модель” человека позволяет успешно работать не только с запомненными и обобщенными знаниями, но и продуцирует алгоритмику их обработки. Современные системы представления знаний отчасти решают эту проблему, комбинируя так называемое декларативное описание знаний с процедуральным описанием и обеспечивая их по возможности тесное взаимодействие. Однако вопросы генерации алгоритмов, оформления их в виде процедур и включения в общие знания практически не развиты в современных системах. Не случайно описанные в обзоре выше системы ориентированы на обработку именно ЕЯ-текстов и практически не рассматривают вопросы анализа текстов программного кода.
Модель мира человека позволяет ему, просмотрев произвольный текст, кратко изложить его содержание (аннотация) или обсудить содержание в процессе диалога. Наоборот, по краткому описанию человек может из большого текста выделить соответствующие этому описанию фрагменты. Например, по запросу “проследить жизненный путь Андрея Болконского”, имея текст произведения “Война и мир”, человек может выбрать фрагменты, релевантные данному запросу. Современные системы, ориентированные на обработку знаний, предлагают решения такого рада задач, но качество решений, мягко говоря, оставляет желать лучшего.
Наконец, для человека работа со знаниями связывается с выдвижением гипотез, их проверкой, уточнением и пересмотром исходных предпосылок. С этой целью после выдвижения достаточно содержательной гипотезы выполняются эксперименты, анализируются их результаты и процесс повторяется. При этом как при экспериментах, так и при анализе могут привлекаться любые другие знания в зависимости от складывающейся ситуации. Современные базы знаний очень далеки от такой работы со знаниями.
Итак, если подходить строго, то полноценная работа со знаниями пока доступна только человеку, а базы знаний следует понимать как метафорический термин, качественно отличающий обычную обработку данных от обработки, ориентированной на использование знаний, аналогично тому как это делает человек. В том же метафорическом (техническом) смысле следует понимать и ряд других терминов, таких как “гипотеза”, “естественно-языковый доступ”, “понимание запроса” и т.д. В научной практике такое техническое использование терминов широко распространено. Примеры из математики – “равномерная непрерывность”, “сходимость ряда” и т.п. Еще более яркий пример – “теория информации”, если речь идет о передаче информации, то передаются именно данные, строго говоря никакой содержательной интерпретации такая передача не выполняет.
5. Cервисно-ориентированная архитектура
5.1.
Общие сведения о СОА
Компоненты SUKI (4.3) не случайно названы сервисами. В настоящее время аббревиатура СОА сервисно-ориентированная архитектура широко рекламируется разработчиками. Утверждается, что компоненты СОА — Web-сервисы, язык XML и многочисленные межплатформенные инициативы — призваны избавить корпоративные подразделения ИТ от медленных, нестабильных и дорогостоящих систем интеграции. Однако в результате непродуманных решений по развертыванию СОА-технологий вполне возможно появление нового поколения систем — таких же медленных, нестабильных и дорогостоящих, аргументированная критика такого рода решений дана в [30].
В силу того, что сети кластеров предназначены для решения крупных масштабных задач и при этом обычно используются разнообразные приложения, проблема их интеграции для решения глобальной задачи остается актуальной. Поэтому вопросы СОА как концептуального плана, так и конкретного планируемого развития (раздел 5.2.) рассматриваются более подробно.
Проблема интеграции в аспекте представления сложных корпоративных систем в виде динамических сервисов, а не жестких структур из тесно переплетенных между собой элементов не обладает существенной новизной, как справедливо отмечено в [30]. Эта тенденция четко прослеживается и в проектах систем с искусственным интеллектом, предлагавшихся в 80-х годах прошлого века, и в моделях взаимодействия распределенных объектов наподобие CORBA, обсуждавшихся в 90-х.
С технической точки зрения СОА обеспечивает интеграцию приложений без
установления жестких взаимосвязей между бизнес-процессами. Знания из одной
структуры данных здесь не встраиваются в бизнес-логику другого процесса.
Наоборот, открытая природа и податливость XML позволяют изолировать требования
к данным со стороны отдельных приложений. В системах СОА все необходимые
сервисы трансляции XML используют ту же “сервисную шину”, что и
бизнес-процессы.
Примером решения сервисной шины промышленного класса является Sonic ESB. Эта шина комбинирует XML, коммуникационные сервисы промышленного класса и СОА, основанную на усовершенствованиях стандартов WEB-сервисов. Утверждается, что по сравнению с ранее используемыми интеграционными брокерами шина Sonic ESB обладает большей гибкостью, эффективностью и простотой в эксплуатации и управлении. Sonic ESB рассматривает все приложения как сервисы, что позволяет поместить на шину и исполнить развитую логику из любого места. Утверждается также, что Sonic ESB позволяет начинать решение интеграционного проекта с незначительного пилота и масштабировать полученные результаты до сколь угодно большого размера промышленного предприятия.
Этот стиль является типичным для СОА, cначала достаточно внедрить технологию в одном подразделении или даже в рамках отдельного проекта. После этого функции сервисно-ориентированной архитектуры нетрудно сделать доступными всему предприятию через трансляторы XML и адаптеры протоколов. В таком случае срочная модернизация других систем не понадобится.
В сервисно-ориентированной архитектуре код,
служащий для связи между процессами, не имеет ничего общего с тем, который
исполняется в этих процессах. Поэтому для ввода в действие нового коммуникационного
протокола достаточно внести изменения только в связную структуру.
Именно это отличает СОА от сервисного подхода, принятого в прежних
схемах обмена электронными данными. Используемые в них форматы сообщений не
содержали самоописания и не позволяли процессам производить селективный
синтаксический анализ по мере необходимости. В результате разработчики зачастую
встраивали коммуникационную логику в логику процессов.
Обычно при построении соответствий между документами различных приложений используются мощные редакторы с средства отладки и тестирования для XML и XSLT. Например, вышеупомянутая Sonic ESB включает редактор преобразований XML-to-XML, устанавливающий соответствия между документами, лишь выполнив серию простых операций по захватыванию и перетаскиванию объектов. Важно, что по мере графического построения соответствий (mapping) между документами XLST-таблица строится автоматически – без необходимости программирования на самом XLST.
Разумеется СОА не обойтись без механизмов обеспечения безопасности и целостности сообщений, эта проблема была особенно острой в начальных версиях протоколов Web-сервисов. Чтобы изменения в связной протокол для обеспечения безопасности не требовало вдаваться в детали защиты и работы каждого коммуникационного элемента в отдельности, обязательно нужны встроенные протоколы и правила.
Microsoft планирует в 2006 году включить в состав Windows XP и Windows Server 2003 продукт
Indigo - высокоуровневую систему обработки сообщений, которое Microsoft
предлагает как привлекательное средство интеграции для построения СОА. Краткие
сведения об Indigo даются в разделе 5.2. Опираясь на Indigo, программисты
смогут писать относительно короткие исходные тексты и при этом предоставлять
пользователям такие важные преимущества сервисов, как надежная доставка сообщений,
асинхронный обмен данными между различными устройствами и приложениями и многое
другое.
Проектировщикам СОА будет недостаточно обеспечить обычную поддержку сервисного стандарта. Сначала им придется определить трудоемкость реализации этого стандарта в том или ином приложении, полностью отвечающем корпоративным требованиям к надежности. По оценке одного из архитекторов проекта Microsoft Indigo для полноценной защиты типичного приложения для .Net без привлечения системной библиотеки разработчику придется написать около 60 тыс. строк кода. С помощью библиотеке Web Services Enhancement объем программного кода существенно сокращается.
Концепция СОА, обещает повысить производительность труда программистов, требуемую давлением современной среды корпоративных ИТ, требующей окупаемости капиталовложений за считанные недели или месяцы, а не кварталы и годы. Сократить сроки окупаемости мешает среди прочего череда корпоративных приобретений и слияний, которая сводит на нет любую попытку унификации архитектуры. Специалисту ИТ приходится без конца заниматься реализацией процессов, созданных по чужому сценарию и требующих срочной и эффективной интеграции. В таких ситуациях становятся просто неоценимыми свободные взаимосвязи между компонентами СОА и возможность перенацеливать данные формата XML.
Рекомендации передового опыта сервисно-ориентированной архитектуры:
— Описывать серверы на основании деловых потребностей, а не технологических функций.
— Отделять бизнес-функции от коммуникационных протоколов, чтобы избежать их жесткой связки.
— Начинать с пилотных проектов Web-сервисов с последующим облачением унаследованных систем в сервисные интерфейсы.
— Функции
безопасности и надежности находить в библиотеках кодов, инфраструктурах и средах сервисной
шины, не отрывая своих программистов от решения более насущных деловых задач.
5.2. Новая коммуникационная подсистема Windows - Indigo
Indigo – это новая коммуникационная подсистема Windows, предназначенная для создания распределенных приложений. Основная задача Indigo – обеспечить взаимодействие частей распределенного приложения. Помимо этого она обеспечивает безопасность, транзакционность и надежность коммуникаций [31].
Серверная часть приложения, использующего Indigo, называется сервисом. Сервис, прежде всего, содержит функциональность, которую необходимо реализовать на сервере (реализацию). Кроме того, он может содержать метаданные, необходимые для его публикации, и контракта – абстрактного описания методов, параметров и возвращаемых значений точки доступа (endpoint). Взаимодействие с клиентом осуществляется посредством сообщений.
Простейший
способ создания как реализации, так и контракта – это разметка обычного класса
специальными атрибутами, ServiceContractAttribute и OperationContractAttribute.
Первым нужно пометить класс, который является сервисом, вторым – методы,
которые будут доступны публично. Отличие от Web-сервисов прежде всего в том , что в Indigo нет
необходимости наследовать класс от специального класса. Необходимость такового
признана архитектурной ошибкой, и вместо наследования предложен атрибут. Это
повышает гибкость решений при построении распределенных приложений. Еще одно
отличие – поддержка сессий теперь задается не для методов, а для сервиса
целиком. Это больше соответствует принципам построения сервисов.
Рассмотренный в [31] пример
генерации исходного кода для Web-сервиса
и аналигичного для Indigo
иллюстрирует, что прокси-класс Indigo намного
компактнее. Вместо фиктивного dateTime в случае WSDL в Indigo введен
полноценный System.DateTime. Базовый класс представляет собой generic-класс,
поэтому нет никаких приведений при обращении к его методам и свойствам, а в сам
прокси-класс включен типизированный интерфейс (это позволит использовать
несколько разных прокси-классов с одинаковыми контрактами). Нет массы
асинхронных методов – функциональность асинхронных вызовов вынесена наружу. Кроме того вместо
конструктора без параметров и жесткой привязки к конкретному URL мы имеем
несколько перегруженных конструкторов, в параметрах которых можно передать
требуемое связывание и точку доступа.
При разработке Indigo Microsoft
опиралась на 4 основных принципа построения сервис-ориентированных
систем [30]:
1. Границы отражены явно. Современные распределенные системы географически могут быть расположены чрезвычайно широко. Скорость и надежность каналов коммуникаций между частями может сильно различаться. Поэтому сервис-ориентированное приложение должно явно выделять процесс преодоления границ между частями системы, вместо того чтобы делать это неявно при вызове метода. Это позволяет избежать проблем, связанных с нестабильностью и низкой скоростью глобальных каналов коммуникаций.
Идеология явного выделения границ коммуникации распространяется не только на различные сервисы различных поставщиков, но и на разработку нескольких сервисов внутри одной компании, поскольку в ходе дальнейшего развития системы может понадобиться использовать эти сервисы удаленно. Упрощение и универсализация сервисов в сервис-ориентированной архитектуре – это жизненно важный момент для создания надежных и легко изменяемых SOA-приложений.
2.
Сервисы автономны. Поскольку части распределенной системы разнесены
очень широко, невозможно гарантировать, что все ее части будут работоспособны,
иметь одинаковые версии и т.п. Поэтому при проектировании таких приложений необходимо
рассматривать как штатную ситуацию отсутствие некоторых сервисов, сбои в
каналах связи или неполные совпадения контрактов. Кроме того, поскольку внутрисистемные
коммуникации могут проходить по открытым каналам связи, необходимы
аутентификация, шифрование и проверка целостности межсервисных сообщений.
3. Сервисы описываются схемой и контрактом, а не классами. Необходимость сохранения работоспособности системы при смене версии сервиса выдвигает дополнительные требования к гибкости описания контракта сервиса. Описание, сходное с ОО-интерфейсами, для сервисов не годится, поскольку не обеспечивает должного уровня совместимости. Поэтому в SOA следует использовать гибкий формат сообщений, снабженный машинно-проверяемыми схемами, а также возможностью передавать дополнительную информацию, не нарушая структуры основной информации, чтобы обеспечить работоспособность уже использующегося кода.
4. Совместимость сервисов определена и основана на политике совместимости. В классическом ООП на совместимость частей кода влияет как структура публичных интерфейсов кода, так и семантика действий, выполняемых этим кодом. В SOA эти два аспекта совместимости объединены в один. Структурная совместимость обеспечивается машинным контролем формата сообщений на соответствие схеме, семантическая – политикой совместимости.
Политика совместимости представляет собой набор машинно-читаемых выражений. Выражения описывают условия и гарантии (называемые утверждениями, assertion), которые должны быть обеспечены для нормального функционирования сервиса. Утверждения политики идентифицируются стабильным глобально уникальным идентификатором, вне зависимости от того, к какому сервису они применяются. Утверждения должно быть достаточно формальными, чтобы обеспечить простую механику их проверки.
Модель
сервисов Indigo
Модель сервисов предназначена для легкого использования Indigo в CLR-коде. Она представляет собой набор атрибутов, предназначенных для разметки контрактов сервиса. Поддерживаются два типа контракта: контракт сервиса и контракт данных. Контракт сервиса описывает способ, которым можно взаимодействовать с сервисом. Для создания контракта сервиса достаточно применить атрибут ServiceContractAttribute к публичному типу, описывающему сервис. Это может быть как реализация сервиса, так и отдельный интерфейс.
Контракт данных описывает структуру сообщения. Этот вид контракта аналогичен XML-схеме, и описывает способ преобразования CLR-типов в сообщения. Для создания контракта данных достаточно пометить тип атрибутом DataContractAttribute, а его поля или свойства, являющиеся частью контракта, атрибутом DataMemberAttribute.
Основной задачей модели сервисов является обеспечение связи между контрактом и пользовательским кодом. Эта задача решается атрибутом OperationContractAttribute. Методы, помеченные этим атрибутом, являются обработчиками определенного типа сообщений. Обработчики могут быть как однонаправленными, так и работающими в режиме запрос-ответ, что определяется значением свойства IsOneWay атрибута. В процессе работы сообщение преобразовывается в типизированный набор параметров, а возвращаемое значение преобразовывается в ответное сообщение.
Еще одной задачей, которую выполняет модель сервисов, является поддержание контекста работы. В понятие контекста входят сессии, поддержка контекста вызова, поддержка транзакций. Наконец, модель сервисов Indigo обеспечивает декларативный механизм связывания сервисов и контроля безопасности взаимодействия.
Системные сервисы и сервисы
сообщений
Indigo
содержит несколько сервисов, предназначенных для упрощения реализации отдельных
аспектов распределенных систем. Например, для обеспечения сложных схем
авторизации с установлением доверительных отношений между различными сервисами
и обменом идентификационной информацией (identity federation). В будущих
версиях Windows будет использоваться подобная схема, основанная на
WS-Federation (протокол обмена идентификационной информацией между
Web-сервисами).
6. О компьютерной лингвистике
Современные результаты в области
компьютерной лингвистики в своей массе не слишком интересны для целей данного
обзора (при внешней релевантности заголовков). Примеры работ “К вопросу о создании интеллектуального
интерфейса с организацией обработки запроса на естественном языке ” [32]
и “Снятие лексико-семантической
омонимии в новостных и газетно-журнальных текстах: поверхностные фильтры и
статистическая оценка”[33] (по материалам конференции “Диалог
Радикальное высказывание по поводу перспектив компьютерной лингвистики в поисковых системах Интернета (переводчик от Гугл) дано по ссылке [http://www.webplanet.ru/news/lenta/2005/823/transoogle.html]. Цитируем: “Поисковые системы лингвистические методы не используют - только статистические - они быстрее, точнее и не требуют создания лингвистических банков данных.” Далее приводится основная идея - если в похожем контексте данная фраза кем-то перевелась с большой вероятностью, то скорее всего она и в данном контексте будет переводиться также. Используя достаточно большую (и постоянно пополняемую) базу переводов, можно добиться высокого качества, не прибегая к сложным лингвистическим методам.
Разумеется, данное высказывание, равно как и негативное отношение к компьютерной лингвистике вообще, слишком экстремально. Однако не следует полностью исключить вероятность достаточно высококачественного технического перевода, используя такой подход по прецедентам. Напомним, что для достижения большого успеха в шахматных программах предполагалось использовать развитые средства искусственного интеллекта (шахматисты утверждали даже, что необходимо моделировать способность к творчеству).
Однако действительность оказалась прозаичнее: используя относительно простые эвристики, специализированные шахматные базы и мощные аппаратные средства удалось создать программы, играющие на равных с людьми - чемпионами мира. Экстраполяция такой ситуации на проблему машинного перевода (разумеется с рядом модификаций) вполне имеет право на существование.
Наиболее
интересными являются направления исследований, выполняемых лаборатории компьютерной
лингвистики, много лет развивающей модель “Смысл - Текст” (Апресян Ю.Д., в
настоящее время руководитель - Богуславский И. М.). Эти направления
ориентированы на фундаментальные вопросы обработки ЕЯ (в частности на машинный
перевод), однако многие результаты исследований имеют несомненный прикладной
интерес.
Основной
научной проблематикой лаборатории является функционирование естественного языка
в качестве средства передачи информации. Фундаментальные исследования
направлены на разработку полной действующей формальной модели языка типа
"Смысл-Текст". Модель должна имитировать языковое поведение человека,
т.е. его способность производить тексты на естественном языке и понимать их.
Компьютерная
версия модели, разрабатываемая в Лаборатории, имеет
вид полифункционального многоязычного процессора, известного под условным
наименованием ЭТАП. ЭТАП состоит из морфологических и комбинаторных словарей
рабочих языков и наборов правил. В идеале правила во взаимодействии со
словарями должны имитировать языковое поведение человека при производстве и
понимании тестов.
Будучи
инструментом решения практических задач в области переработки текстов на
естественных языках, такие системы, с другой стороны, служат экспериментальным
полигоном для корректировки лингвистических описаний и получения принципиально
новых лингвистических знаний.
Демонстрационная версия системы ЭТАП доступна по адресу http://proling.iitp.ru.
В 2004 году работа Лаборатории разворачивалась по трем
основным направлениям: развитие теоретических проблем лексикографии, построение
глубоко аннотированного корпуса русского языка и совершенствование
функциональных возможностей системы ЭТАП. Всего в лаборатории велись
исследования по пяти научным темам.
1. Тема «Разработка
новой теории и аппарата лексических функций для целей компьютерной лингвистики».
2. Тема «Разработка
теории и словаря глагольного управления для целей автоматического анализа и
синтеза текстов на русском языке.
3. Тема «Морфо-синтаксическая
и лексико-семантическая разметка русских текстов».
4. Тема «Разработка
интерактивной системы разрешения лексической неоднозначности для машинного
перевода и других приложений».
5. Тема «Разработка
модуля синтактико-семантического анализа для системы многоязычной коммуникации
в Интернете, основанной на Универсальном сетевом языке (UNL)».
Последняя тема вызывает особый интерес в аспекте основных задач настоящих
материалов. Искусственный язык для представления значений (UNL), должен выполнять
роль языка-посредника для всех рабочих языков системы. В ходе исследования был
разработан массив правил, предназначенных для преобразования текстов на русском
языке в гиперграфы UNL. Эти правила составляют важную часть UNL-модуля,
разрабатываемого в качестве отдельной подсистемы лингвистического процессора
ЭТАП-3. Вместе с русско-UNL словарем эти правила обеспечивают эффективное построение
текстов UNL и в конечном счете организацию интерфейса между русским языком и
всеми остальными рабочими языками системы.
7.
Когнитивные методы принятия решений
Сложные социально-политические и экономические системы не удается описывать чисто количественными методами и соответствующими математическими моделями. Практическое отсутствие детального количественного описания происходящих в них процессов требует привлечения информации качественного характера. Системы искусственного интеллекта в начале своего развития предлагали возможности использования такой информации, организуя ее методами представления знаний. Были разработаны формализмы языка исчисления предикатов, семантических сетей, фреймов и продукционных правил.
Однако постепенно выяснилось недостаточность таких формализмов и стали предприниматься попытки по-другому взглянуть на проблему представления знаний, одна из наиболее развитых попыток связана с так называемыми когнитивными методами. Эти методы синтезируют психологические подходы к способности человека познавать окружающий мир и достижения ИИ по моделированию таких способностей. Основы и проблемы когнитивного подхода на современном этапе достаточно подробно представлены в материалах четвертой Международной конференции “Когнитивный анализ и управление развитием ситуаций” [34], проходившей в октябре 2004 в Москве.
Когнитивность как "разум" означает "способность думать, объяснять, обосновывать действия, идеи и гипотезы". Исследования вопросов построения интеллектуальных систем со сложным поведением привело к необходимости использования когнитивных концепций, таких, как убеждения, желания, намерения, а также методов накопления знаний путем самообучения и ментальных методов принятия решений.
Спектр применения когнитивных методов для поддержки принятия решений весьма широк, далее в разделе 8.1. рассматриваются вопросы использования этих методов в области политики, а в 8.2. – в сфере бизнесе.
Важно отметить, что перспективным направлением в использовании когнитивных методов является моделирование сложного интеллектуального поведения реализуемого в многоагентных системах, построенных с использованием интеллектуальных агентов на когнитивных концепциях. Естественно предположить, что коллектив таких агентов может решать значительно более сложные задачи, чем одиночный агент. Спроектированные таким образом компоненты способны, по мнению специалистов-когнитологов реализовать поведенческие процессы, имитирующие поведение человека при выполнении сложных работ.
Техническая реализация такого подхода требует разработки специальных алгоритмических и программных средств. Предлагаются базовые архитектуры, а также нейрологические средства для построения когнитивных компонентов, структур и агентов [35]. Очевидна целесообразность при реализации таких архитектур использовать многопроцессорные системы.
Когнитивные методы существенно
изменяют парадигму, опирающуюся только на логику. Эта парадигма в своей основе он имеет
представление о категоризации, как процессе, сводящему мышление к представлению
понятий абстрактными символами (концептами, факторами) и манипулированию ими. Когнитивные подходы к категоризации
основываются на
парадигме, констатирующей, что присущая человеку умственная процедура
категоризации опирается, прежде всего, на человеческий опыт и воображение,
которые не могут в существенной степени характеризоваться просто в терминах абстрактных
символов. Мы понимаем мир не только в терминах отдельных вещей, но и в терминах
категорий, которым мы приписываем статус реальности (кризис и стабильность,
долг и неблагодарность).
Говоря
о категориях (классах, концептах), когнитивный подход учитывает прежде всего
следующие отличительные моменты:
члены категории могут быть связаны между
собой, и влиять друг на друга, даже если у них нет общего (формального)
сходства;
представительность
разных членов категории может быть различной;
связанные
между собой значения слов могут образовывать категории;
как
правило, категории не имеют четких границ и принадлежность к ним выражается
градуально, нечетко;
свойства
категорий отражают сущность способностей человека, его поведения в социальном
окружении, понятия не существуют независимо от мыслящих существ;
в
некоторых мыслительных процессах часть категории может кодировать, замещать всю
категорию.
Когнитивные модели используют именно такое категоризированное пространство. Они позволяют оперативно строить и успешно поддерживать сложные корпоративные решения, например, в случае, когда проблема представляется в виде факторов и нечетких влияний факторов друг на друга. Когнитивная модель позволяет быстро отвечать на вопросы типа: “Какие действия надо предпринять, чтобы уменьшить инновационный риск?” или “Что будет, если приобрести такие-то ценные бумаги?”.
В онтологии (или представлении
знаний) когнитивный подход наряду с обычными описаниями объектов, свойств и
отношений широко использует такие категории
как воздействия (то, что существенно меняет
свойства или отношения предметов воздействия), превращения (переходы объектов или субъектов
в иное состояние с иными свойствами и отношениями), социосфера (отношения и взаимодействия между
людьми, в том числе по поводу материальных предметов и идей), психосфера
(сознание, психика и общение людей), культуросфера (как пространство
идей, в том числе религиозных, и шире - образцов, используемых в человеческих
обществах);
7.1. Когнитивные методы в социально-политической сфере
В военной области и области информационной безопасности применение когнитивного анализа и моделирования обещает противостоять стратегическому информационному оружию, распознавать конфликтные структуры, не доводя конфликт до стадии вооруженного столкновения.
По оценкам специалистов по
использованию когнитивных методов в современном мире важным фактором является
Стратегическое Информационное Оружие (СИО) второго поколения [36]. СИО второго поколения
представляет собой независимый, кардинально новый тип стратегического оружия,
появившийся в результате информационной революции и применяемый на новых
стратегических направлениях (например, экономическом, политическом,
идеологическом и др.). Время воздействия таким оружием может составлять гораздо
больший срок – месяц, год и более. СИО второго поколения будет способно
противостоять многим другим видам стратегического оружия и будет составлять
ядро стратегических вооружений.
Складывающиеся в результате применения СИО-2 ситуации представляют собой угрозу безопасности России и характеризуются неопределенностью, неясной и нечеткой структурой, влиянием большого числа разнородных факторов и наличием множества альтернативных вариантов развития. Это приводит к необходимости применить нетрадиционные методы, позволяющие изучать геополитические, информационные и др. процессы, протекающие в России и мире, в совокупности и взаимодействии как между собой, так и с внешней нестабильной средой.
Когнитивное моделирование предназначено для
структуризации, анализа и принятия управленческих решений в сложных и
неопределенных ситуациях (геополитических, внутриполитических, военных и т.п.),
при отсутствии количественной или статистической информации о происходящих
процессах в таких ситуациях. Когнитивное моделирование позволяет в экспресс
режиме в короткие сроки на качественном уровне:
оценить ситуацию и провести анализ взаимовлияния действующих факторов, определяющих возможные сценарии развития ситуации;
выявить тенденции развития ситуаций и реальные намерения их участников;
- разработать стратегию использования тенденций развития
политической ситуации
в национальных интересах России;
- определить возможные механизмы взаимодействия участников ситуации для
достижения ее целенаправленного развития
в интересах России;
- выработать и обосновать направления
управления ситуацией в интересах России;
- определить возможные варианты
развития ситуации с учетом последствий принятия
важнейших решений и сравнить их.
Применение
технологии когнитивного моделирования позволяет действовать на опережение и не
доводить потенциально опасные ситуации до угрожающих и конфликтных, а в случае
их возникновения - принимать рациональные решения в интересах субъектов России.
Для
задач, связанных с организационными системами, проблема неопределенности в
описании и моделировании функций участников является не методологической, а
внутренне присущей самому предмету исследований. Возможны различные постановки
задачи об управлении ситуацией в зависимости от полноты доступной участникам
информации о ситуации и об остальных участниках, в частности для поиска резонансного
и синергетического эффектов, когда улучшение ситуации при одновременном
воздействии на нее
нескольких участников больше
«объединения» положительных эффектов от каждого из участников по
отдельности.
7.2. Когнитивные методы в экономике
Применение когнитивных технологий в экономической сфере позволяет в сжатые сроки разработать и обосновать стратегию экономического развития предприятия, банка, региона или целого государства с учетом влияния изменений во внешней среде. В сфере финансов и фондового рынка когнитивные технологии позволяют учесть ожидания участников рынка. Достаточно содержательный пример системы когнитивного моделирования для целей бизнеса описан в [37].
Отмечено, что при отсутствии детального количественного описания процессов, происходящих в сложных системах и качественном характере информации можно, тем не менее, для каждой такой системы указать:
- совокупность некоторых основных (базисных) факторов, временные
изменения и взаимодействие которых интересуют аналитика;
- качественное описание непосредственного влияния факторов друг на
друга.
![]() Как
правило, системному аналитику доступна лишь качественная информация о текущем
состоянии того или иного фактора. Характер влияния факторов друг на друга может
быть описан с помощью лингвистических переменных типа:
Как
правило, системному аналитику доступна лишь качественная информация о текущем
состоянии того или иного фактора. Характер влияния факторов друг на друга может
быть описан с помощью лингвистических переменных типа:
- "влияние положительное", т.е. изменение одного фактора в
какую-либо сторону (увеличение, уменьшение) вызывает изменение другого
фактора в ту же сторону (увеличение, уменьшение);
- "влияние отрицательное", т.е. увеличение (уменьшение) одного
фактора вызывает уменьшение (увеличение) другого фактора.
![]() Важнейшей особенностью
возникающих ситуаций в бизнесе является наличие в них мыслящих участников,
причем каждый из них по-своему представляет ситуацию и принимает те или иные
решения, исходя из "своего" (виртуального) представления. Это
приводит к тому, что процессы в ситуации ведут не к равновесию, а к никогда не
заканчивающемуся процессу изменений. Отсюда следует, что достоверное предсказание
поведения процессов в ситуации невозможно без учета оценки этой ситуации ее участниками
и их собственных предположений о возможных действиях. Эту особенность
финансовых задач Дж. Сорос назвал рефлексивностью [38].
Важнейшей особенностью
возникающих ситуаций в бизнесе является наличие в них мыслящих участников,
причем каждый из них по-своему представляет ситуацию и принимает те или иные
решения, исходя из "своего" (виртуального) представления. Это
приводит к тому, что процессы в ситуации ведут не к равновесию, а к никогда не
заканчивающемуся процессу изменений. Отсюда следует, что достоверное предсказание
поведения процессов в ситуации невозможно без учета оценки этой ситуации ее участниками
и их собственных предположений о возможных действиях. Эту особенность
финансовых задач Дж. Сорос назвал рефлексивностью [38].
При построении когнитивной модели исследуемая ситуация представляется в виде формальных триад "исходные предпосылки - наше воздействие на ситуацию - полученный результат с учетом ситуации". Каждый элемент такой триады является определенным вектором из соответствующего пространства признаков или действий. Подобное представление ситуации является наиболее трудоемкой подготовительной частью работы, требующей привлечения либо соответствующих экспертов-аналитиков, либо обработки массивов информации, поступающей из СМИ (печать, радио, телевидение, служебные каналы и т.п.).
При структуризации, или концептуализации знаний проектируется структура полученных знаний о предметной области, т.е. составляется список базисных (основных) понятий, выявляются отношения между ними, определяются стратегии принятия решений в данной предметной области и ее связи с окружающим миром. Иначе говоря, на этом этапе составляется неформальное описание знаний о предметной области, которую можно наглядно изобразить в виде графа, таблицы, текста и т.д. При формализации знаний инженер-когнитолог выбирает один из этих способов, адекватный его представлению о предметной области.
В процессе извлечения знаний происходит взаимодействие эксперта - источника знаний с когнитологом (инженером по знаниям). Оно позволяет проследить за ходом рассуждения специалистов при принятии решений и выявить структуру их представлений о предметной области. Извлечение - это процедура, в ходе выполнения которой когнитолог, имеющий опыт в области когнитивной психологии, системного анализа, или математической логики, создает "скелетную" модель предметной области, наполняемую на последующих этапах конкретными сведениями об объектах этой области.
Схемы, интерпретирующие мнение и взгляды лица, принимающего решения, называются когнитивной картой. На математическом языке когнитивная карта называется знаковым (взвешенным) ориентированным графом. Когнитивная карта отображает причинно-следственные связи в сложной экономической или социальной системе.
Проблема количественной оценки причинно-следственных связей в бизнесе сложна и трудоемка, но часто она и не требуется; так в социологии для получения числовых характеристик требуется провести предварительное анкетирование с последующей статистической обработкой. Содержательные выводы можно получить, пользуясь качественными оценками, сформулированными на концептуальном уровне на основе интуиции и опыта аналитика, и результатами анализа финансовых рынков. В результате будут выяснены тенденции основных процессов в ситуации.
Когда когнитивная модель финансово-экономической ситуации для бизнеса построена, необходимо проверить, насколько эта модель адекватна реальной ситуации. Такая проверка осуществляется следующим образом. Допустим, что между базисными (фундаментальными) факторами, являющимися вершинами графовой модели, существуют отношения, которые можно трактовать как непреложные факты в рассматриваемой предметной области. Эти отношения, как правило, формируются в виде продукций типа:
![]() ЕСЛИ
X1 V X2 V... VХk, то X1,
ЕСЛИ
X1 V X2 V... VХk, то X1,
![]() где
Xi - некоторая характеристика базисного фактора Vi (например, предельная величина
фактора, знак приращения фактора и т.п.).
где
Xi - некоторая характеристика базисного фактора Vi (например, предельная величина
фактора, знак приращения фактора и т.п.).
![]() Совокупность таких продукций
отражает базисные знания о данной предметной области. Графовая модель считается
адекватной реальной ситуации, если в модельных процессах не нарушается ни одна
из продукций базисных знаний. Проверка адекватности модели необходима для
получения достоверных прогнозов развития той или иной ситуации на рынке фирмы.
Полнота проверки модели на адекватность зависит от полноты базисных знаний.
Совокупность таких продукций
отражает базисные знания о данной предметной области. Графовая модель считается
адекватной реальной ситуации, если в модельных процессах не нарушается ни одна
из продукций базисных знаний. Проверка адекватности модели необходима для
получения достоверных прогнозов развития той или иной ситуации на рынке фирмы.
Полнота проверки модели на адекватность зависит от полноты базисных знаний.
Типичные этапы решения задачи при моделировании ситуаций в бизнесе приведены в [37]:
- Построение когнитивной (познавательной)
модели исследуемой ситуации:
- выделение и обоснование базисных
факторов ситуации;
- установление и обоснование взаимосвязей
факторов;
- построение графовой модели ситуации.
- Структурную интерпретацию проблем,
требующих решения в исследуемой ситуации.
- Поиск и обоснование стратегий достижения
цели в стабильных или изменяющихся ситуациях:
- выбор и обоснование желаемых целей в
условиях неопределенности;
- выбор мероприятий (управлений) для
достижения цели;
- анализ принципиальной возможности
достижения цели из текущего состояния ситуации с использованием выбранных
мероприятий;
- анализ ограничений на возможности
реализации выбранных мероприятий в реальной действительности;
- анализ и обоснование реальной
возможности достижения цели;
- выработка и сравнение стратегий
достижения цели.
- Поиск и обоснование стратегий решения
проблем в конфликтных ситуациях:
- анализ целей участников конфликта;
- анализ ресурсов участников конфликта;
- анализ и обоснование возможностей образования коалиций среди участников конфликта;
- анализ и обоснование различных сценариев поведения участников конфликта.
5. Обоснование возможных сценариев развития ситуации.
Эксперименты с моделью в зависимости от исходной ситуации включают различные постановки задач о достижении цели путем выбора тех или иных управляющих воздействий. Эти управляющие воздействия могут быть кратковременными (импульсными) или продолжительными (непрерывными), действующими вплоть до достижения цели. Возможно и совместное использование импульсных и непрерывных управляющих воздействий.
Комментарий к разделам 5 и 7.
Данные разделы не относятся непосредственно к проблемам структуризации текстов. Однако описываемые там методы, ориентированные на синтез психологических подходов к способности человека познавать окружающий мир и достижений ИИ по моделированию таких способностей, представляют несомненный интерес для разработки этой проблемы.
Структуризации, анализ и принятие решений в сложных и неопределенных ситуациях с ориентацией на качественную информацию, а также использование онтологий с понятиями, трудно представляемыми в стандартных системах работы со знаниями (воздействия, намерения, социосфера и т.п.) является несомненным достоинством когнитивных методов.
Описываемый в разделе 5 сервисно-ориентированный подход отражает современный подход к интеграции систем (в частности баз данных) промышленного уровня с использованием XML. Как указано выше, атака на проблему интеграции велась и в 80 и в 90-ые годы (именно тогда появился термин “интероперабельность” и средства описания интегрируемых баз данных на концептуальном уровне).
Отнюдь не умаляя достоинств XML и сервисно-ориентированного подхода, отметим, что сам по себе XML вряд ли может претендовать на полноценный язык представления знаний. Требуется еще достаточно мощная поддержка в виде интерпретирующей системы, обеспечивающей работу с XML-структурами. Примеры: (MathML для записи математических формул, CML – для записи химических формул и т.д.).
Однако значение языка XML не следует недооценивать, использование его в качестве инструментального средства для создания прикладных баз знаний представляется весьма перспективным, разумеется при достижении концептуальными (фундаментальными) исследованиями соответствующей степени зрелости.
8. Заключение
В заключение еще раз вернемся к центральной проблеме ИИ – проблеме представления знаний. Эта проблема еще далека от удовлетворительного решения. Классические подходы, разработанные еще около 30 лет назад, включают формулы языка исчисления предикатов, продукционные правила (экспертные системы), семантические сети и фреймы. Эти подходы (как и их недостатки) широко известны и здесь не обсуждаются. Отметим только, что за истекший период упомянутые подходы практически не претерпели существенных изменений. Во всяком случае ни в одном из подходов не удалось разработать общепризнанный стандарт для представления знаний. Именно отсутствие такого стандарта существенно затрудняет сравнение систем, как уже отмечалось выше.
Однако помимо классических подходов, упомянутых выше (формулы исчисления предикатов, продукционные правила, семантические сети, фреймы), представляют интерес разработки стандартов в идейно близких направлениях (data mining). Наиболее интересен один из стандартов унификации интерфейса для объектных языков программирования, а именно CWM Data Mining. Этот стандарт (сокращение от Common Warehouse Metamodel) разработан консорциумом OMG для обмена метаданными между различными программными продуктами и репозитариями, участвующими в создании корпоративных Decision Support System (Систем Поддержки Принятия Решений - СППР) [39], [40].
Он основан на открытых объектно-ориентированных технологиях и стандартах, использует UML (Unifed Modeling Language) в качестве языка моделирования, XML и XMI (XML Metadata Interchange) для обмена метаданными и язык программирования JAVA для реализации моделей и спецификаций. В настоящее время существует единый официально признанный стандарт CWM 1.0.
В основе CWM лежит модельно-ориентированный подход к обмену метаданными, согласно которому объектные модели, представляющие специфические для конкретного продукта метаданные, строятся в соответствии с синтаксическими и семантическими спецификациями некоторой общей метамодели. Это означает наличие общей системы фундаментальных понятий данной области, с помощью которых любой продукт должен “понимать” широкий спектр моделей, описывающих конкретные экземпляры метаданных.
CWM имеет модульную структуру, причем под модулем понимается отдельная метамодель (или средство моделирования). Например, для представления метаданных процессов преобразований и загрузки данных в хранилище (Warehouse) используется метамодель “Преобразование”, для спецификации особенностей многомерного анализа – метамодель “OLAP” и т.д. Уже эти общие сведения позволяют рассматривать такой стандарт как несомненное движение в сторону систем представления знаний и создания баз знаний. В то же время оценка понятийного базиса таких стандартов и возможности их использования при формировании баз знаний достаточно трудоемки. Однако учет средств описания такого рода стандартов и методологии их создания представляет несомненный интерес для разработчиков по сути экспериментальных баз знаний.
Литература.
|
[1] |
Интеллектуальная программа для поиска фактов в тексте, RCO Fact Extractor |
|
[2] |
СРЕДСТВА ИНФОРМАЦИОННОГО ПОИСКА И НАВИГАЦИИ В БОЛЬШИХ МАССИВАХ НЕСТРУКТУРИРОВАННОЙ ИНФОРМАЦИИ, Липинский Ю.В. компания “ Гарант-Парк-Интернет ” |
|
[3] |
Поисковые возможности Excalibur RetrievalWare, Чибисов А., Открытые системы, #05/1996 |
|
[4] |
АйТи и Convera Technologies International Ltd заключили партнерское соглашение, 19.05.2005 |
|
[5] |
Content Extracting Technology - технология автоматического
понимания текстов |
|
[6] |
Система автоматизированного извлечения знаний из
текстов на естественном языке, А.В.
Нечипоренко, А.О. Русин, Компания «НооЛаб», Новосибирск, Россия,
Международная конференция «Информационные системы и технологии» |
|
[7] |
Извлекая знания из хаоса информации, Андрей
Колесов, 2 декабря, 2003 |
|
[8] |
Язык онтологий в Web, Журнал "Открытые системы", #02, 2004 год |
|
[9] |
OWL, язык веб-онтологий. Руководство. Рекомендация W3C 10 февраля 2004. Перевод исходной английской версии |
|
[10] |
http://www.w3.org/TR/owl-guide/ - последняя английская версия |
|
[11] |
Медиалогия
on-line система анализа информации из открытых источников: газет, журналов,
информационных агентств, интернет-ресурсов, радио и телевидения |
|
[12] |
Искусственный интеллект вычислит террористов, 17 мая 2005, media-online.ru |
|
[13] |
Интернет следующего поколения, Сергей Кузнецов, 2001 INVENTA |
|
[14] |
Ссылка на отчет Гагарина по освоению UIMA |
|
[15] |
Unstructured
InformationManagement Architecture (UIMA) SDK User's Guide and Reference, IBM |
|
[16] |
C++
Enablement for UIMA Components – QuickStart, IBM |
|
[17] |
IBM
Unstructured Information Management Architecture (UIMA), SDK v1.2.3 |
|
[18] |
Модель информационной системы бизнес-разведки, Сергей
Киселев, Открытые системы № 5-6, |
|
[19] |
Component Services for Knowledge Integration in UIMA (a.k.a. SUKI) From Text Analysis to Knowledge, 2005 IBM Corporation |
|
[20] |
A Case
for Automated Large Scale Semantic Annotation, Stephen Dill, Nadav Eiron, and other, |
|
[21] |
|
|
[22] |
J.
William Murdock, Paulo Pinheiro da Silva, David Ferrucci, Christopher Welty
and Deborah
L. McGuinness. Encoding Extraction as Inferences. In Proceedings of AAAI
Spring Symposium on Metacognition on Computation, AAAI Press, |
|
[23] |
Analysis
Workbench (SAW): Towards a Framework for Knowledge Gathering and Synthesis.
Proceedings of the International Conference on
Intelligence Analysis. |
|
[24] |
Курбатов С.С.
Автоматизированное построение естественно-языкового интерфейса для реляционных баз данных. Новости
искусственного интеллекта, № |
|
[25] |
Курбатов С.С. Формирование концептуальной модели для реляционных баз данных на основе анализа естественно- языковых текстов, Международный конгресс “Искусственный интеллект в XXI веке”, ICAI’ 2002, М., Физматлит, 2002. С. |
|
[26] |
Курбатов С.С. Априорная модель данных в реляционных базах,
Новости искусственного интеллекта, № |
|
[27] |
Курбатов С.С. Автоматический анализ схемы и данных
реляционных баз, Новости искусственного интеллекта, № |
|
[28] |
С.С. Курбатов,
Инструментальные средства для автоматизированного построения ЕЯ-интерфейса, в
печати |
|
[29] |
Информция и знания: невидимая грань, Игорь Ашманов |
|
[30] |
Питер Коффи, СОА: новое время — новые песни, Компьютерная неделя, 25 – 31 января, 2005, № 2(484), Москва |
|
[31] |
Корявченко А., Первое знакомство с новой коммуникационной подсистемой Windows, RSDN Magazine #1-2005. |
|
[32] |
К вопросу о создании интеллектуального интерфейса с
организацией обработки запроса на естественном языке, Блувштейн Д. В. конференции “Диалог |
|
[33] |
Снятие лексико-семантической
омонимии в новостных и газетно-журнальных текстах: поверхностные фильтры и
статистическая оценка, Кобрицов Б.П., Ляшевская О.Н., Шеманаева О.Ю. ВИНИТИ
РАН, конференции “Диалог |
|
[34] |
4-ая международная конференция «Когнитивный анализ и управление развитием
ситуаций» CASC’2004, Москва, октябрь |
|
[35] |
Когнитивные концепции и их использование в технических интеллектуальных системах, Л.А. Станкевич |
|
[36] |
И.В. Прангишвили, директор ИПУ РАН, академик ГАН,
«Когнитивный анализ моделей развития российского общества и управления его
эффективностью», материалы 4-ая
международной конференции
«Когнитивный анализ и управление развитием ситуаций» CASC’2004,
Москва, октябрь |
|
[37] |
Технологии информационного общества в действии: применение когнитивных методов в управлении бизнесом, В.И. Максимов, С.В. Качаев, Институт проблем управления |
|
[38] |
Дж. Сорос,
"Алхимия финансов" ,М.: "Инфра", |
|
[39] |
Методы и модели анализа данных: OLAP и Data Mining (+ CD), Барсегян А.А. |
|
[40] |
Стандарт OMG CWM для обмена метаданными в хранилищах данных и его практическое применение, Горчинская О. Ю., Oracle, Москва |
|
[41] |
Курбатов С. С., Подмножество SQL-запросов для ЕЯ-интерфейса к базам данных и проблема его расширения, в печати |
Дополнительный материал 2006 – 2007 гг
Во введении отмечалось, что задача реализации
соответствующих алгоритмов на параллельных системах (сеть кластеров)
рассматривается как фоновая. Тем не менее эта задача приобретает все большую
значимость. Поэтому в дополнительном материале основное внимание уделено очень
краткой характеристике работ по созданию системы высокоточного
интеллектуального поиска, индексации и анализа информации для поддержки
принятия решений (подсистемы VIP
ИСИДА). Характеристика использует материалы презентации соответствующих
подсистем.
В этих системах разрабатываются
методы, позволяющие искать, накапливать, структурировать и анализировать
большие объемы текстовой информации. Структурированная информация и построенные
на ее основе когнитивные модели позволят (в дальнейшем) использовать результаты
работы системы для поддержки принятия решений. При этом весьма важно, что
система существенно ориентирована на параллельные
алгоритмы обработки и высокопроизводительные аппаратные платформы.
В частности параллельная обработка данных предполагает:
n Параллелизм на уровне документов для высокой производительности и снижения накладных расходов
n Разбиение документов для балансировки нагрузки
n Выделение сервисных узлов для выполнения отдельных функций по необходимости
Для организации параллельных вычислений и решения задачи синхронизации используются средства PVM (Parallel Virtual Machine).
Для эффективного применения низкоуровневых интерфейсов библиотеки PVM созданы высокоуровневые средства PVM-взаимодействия приложений с вычислительной средой.
Реализованные в системе инструментальные средства включают:
n редактор ресурсов знаний
n редактор контекстных правил извлечения информации
n визуальное средство конфигурирования
n отладчик контекстных правил извлечения информации
n среда тестирования и оценки качества аналитических систем
n средство демонстрации работы подсистемы
Экспериментальная проверка системы выполнялась на кластерах, было использовано около 1,5 млн. документов. Результаты тестирования оцениваются удовлетворительно как по качеству, так и по времени обработки.
Данная работа не завершена, ее окончание
планируется на