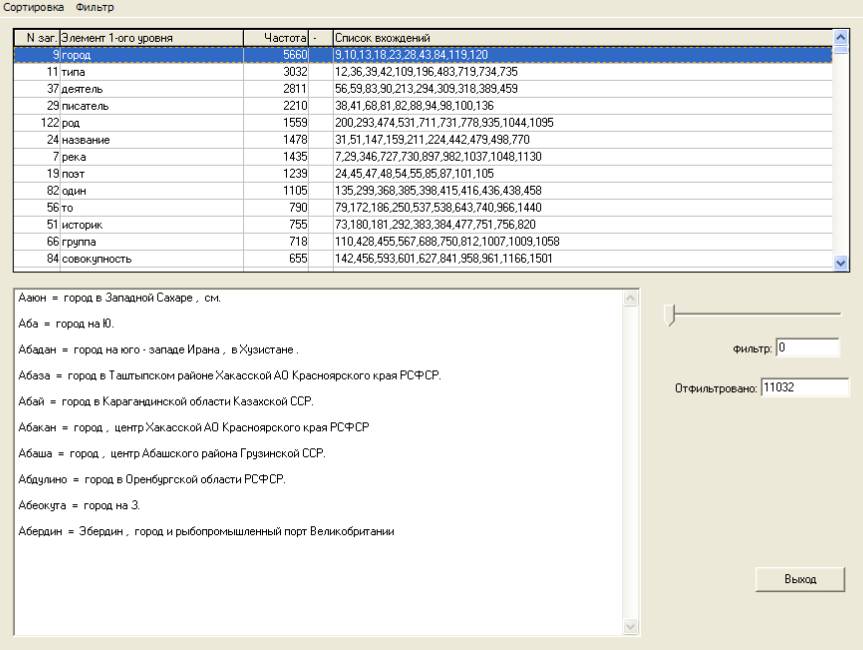
Рис. 1. Элементы 1-ого уровня иерархии.
Элементы отфильтрованы по частоте вхождения в именную группу, выделенную автоматически в качестве описания (возможного) входного понятия (также возможного). Список вхождений содержит номера первых заголовков (именнных групп), а входные понятия и тексты именных групп (из списка вхождений). Применяемые при автоматическом выделении алгоритмы не были оформлены как эвристики, скорее их следует трактовать как “врожденные” механизмы для примитивного быстрого начального анализа, дающего лишь первое приближение и безусловно требующего уточнения в дальнейшем.
На рис. 2 приведено окно, вызываемое для выбранного элемента 1-ого уровня. Верхние панели отражают, соответственно, входное понятие, именную группу (обычно этот 1-ое предложение) и элемент иерархии. Нижняя панель содержит предложения статьи БСЭ (ограничение по общей длине текста). Центральная часть этой панели иллюстрирует вызоы меню, смысл которого в основном очевиден из пунктов. Исключение представляет лишь пункт “Исходная статья БСЭ”, выбор которого загружает WORD-файл с исходным текстом стать БСЭ.
Кнопки “Вперед” и “Назад” позволяют проходить по списку вхождений с выводом соответствующих описаний. Наглядное представление 1-ого уровня иерархии позволило быстро выявить типичные ошибки при автоматическом формировании иерархии и выявлении ядра именной группы и сформулировать соответствующие эвристики для их исправления. Представляли также интерес статистические данные по ошибочным ситуациям. До исправления ошибок была снята копия текущего состояния иерархии, построенной при весьма грубых предположениях относительно морфологии и ядра именных групп. Однако был интересен именно процент правильных догадок при таком грубом подходе.
Типичные примеры ошибок выявляются естественно при малых частотах вхождения. Один из таких примеров отражен на рис. 3., частота минимальна – 1. Ошибка в неверно выделенном ядре именной группе, по сути задающей синоним входного понятия. Аналогичная ошибка для “Ферментопатии” – “энзимопатии , заболевания”. Для устранения таких ошибок требуются достаточо тонкие эвристики.
При анализе ошибок полезен
броузер, приведенный на рис. 4 (под базисными понимаются словоформы, входящие в
исходное понятие или в первую именную
группу). Например, тривиальная ошибка быстрого анализа для словоформы
“алфавитов” выявляется после фильтрации “по основе”, выдающей “алфавитов”,
“алфавита” и “алфавите”, т.е. самой словоформе “алфавит” не приписан
морфологический класс. Это подтверждает рис.4, на котором отражен результат
сортировки по алфавиту и выделен фрагмент словоформ “алфавит”. Стиль отработки
ошибок заключается в следующем:
1) простые, легко алгоритмизуемые ситуации исправляются непосредственной модификацией программных кодов;
2) для более сложных случаев реализуются эвристики
3) для случаев, требующих интеллектуальной обработки, формируется описание на языке представления знаний (ЯПЗ), которое
в дальнейшем должно использоваться универсальной интерпретирующей программой (УИП). Теоретически эта программа
должна быть способна по описанию на ЯПЗ не только выполнять набор эвристик, но и генерировать примеры по описаниям,
а затем запускать механизмы обобщения и формирования новых гипотез.
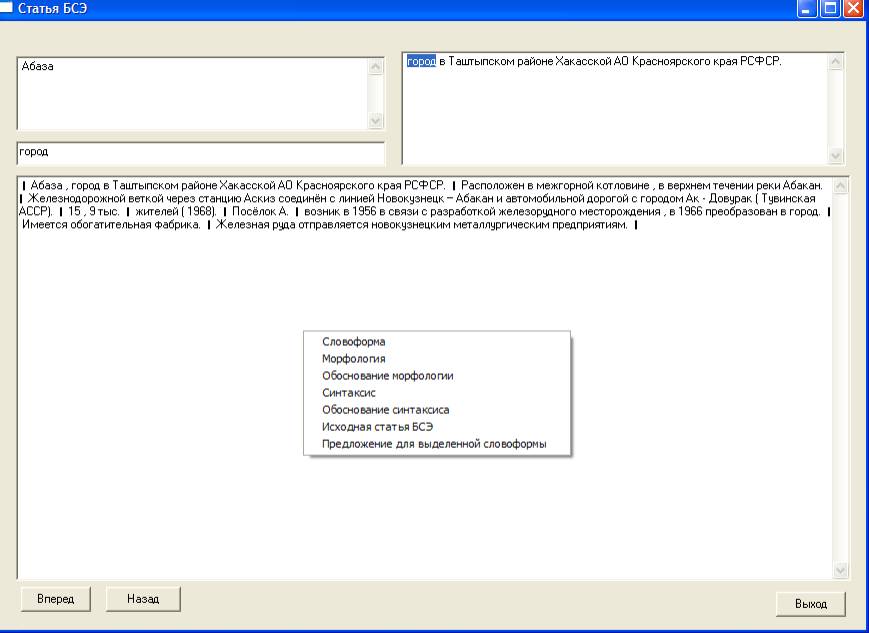
Рис. 2. Предложения (предполагаемые) статьи БСЭ, описывающие входное понятие.
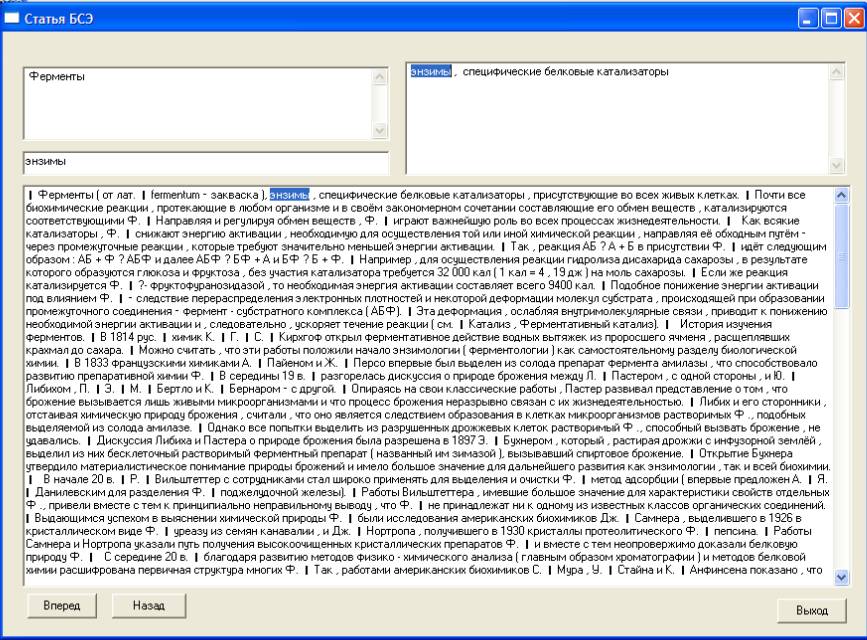
Рис. 3. Иллюстрация типичной ошибки.
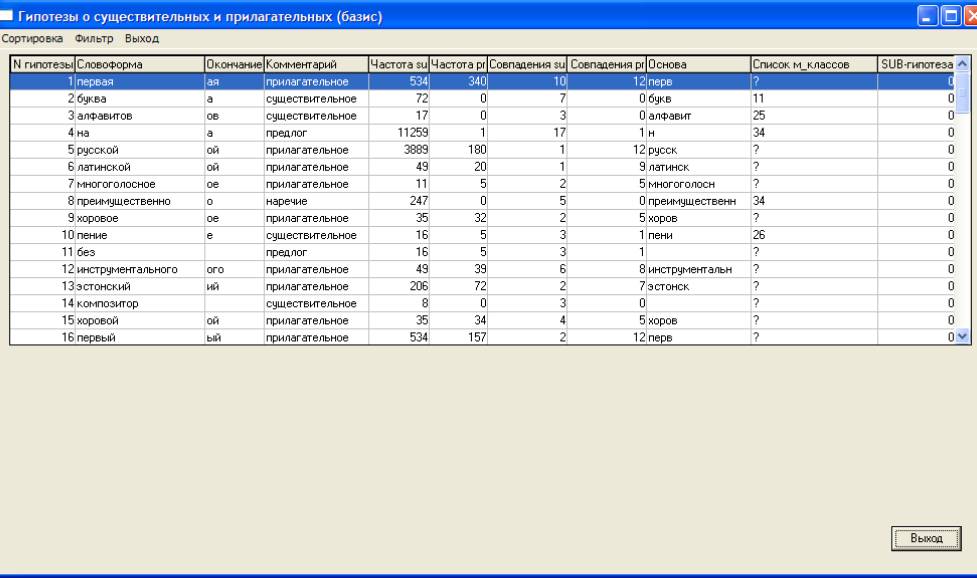
Рис. 4. Базисные словоформы (входное понятие и 1-ое предложение, точнее именная группа) и
предположения о их возможных морфологических характеристиках.
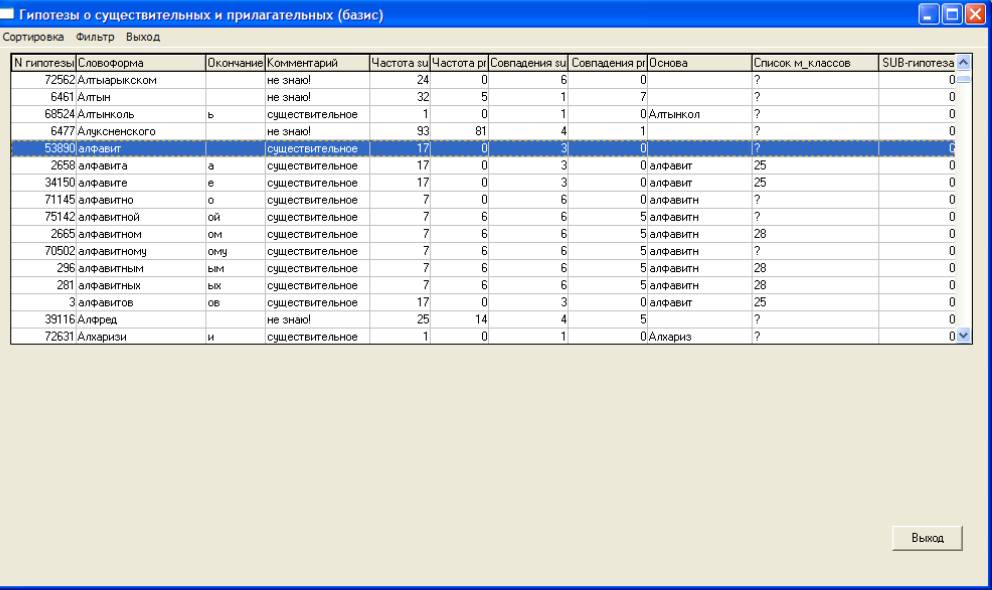
Рис.5. Броузер предположений о базисных словоформах.